Convenient runtime analysis and error checking with C-RUN
This article will explain the basic concepts of runtime analysis and dynamic runtime error checking and look into why it might be a good idea to use such techniques when developing embedded applications. C-RUN is a product in the IAR Systems product portfolio that takes runtime analysis and runtime error checking to new levels of usability.
Background
We all know that software contains errors. We also know that we often spend too much time in testing and especially the debugging phase, trying to track down the really tricky issues. This situation is captured by the 80/20 rule, we spend 80% of the time developing the code and then the remaining 20% testing and debugging… Joking aside, anything that can help us in reducing the last 20% will help us deliver more robust software faster.
A touch of class
When speaking about software errors and defects it helps to have a classification of what kind of errors we are dealing with. In this text we will not speak about specification errors, i.e. have we specified and built the right thing? This is of course a very interesting class of errors in their own right and much has been written on how to collect, organize, work with, implement and test complex requirements in code. However, here we will focus on data manipulation issues; i.e. the things that might go wrong on a lower level when implementing those high-level requirements.
To set the scene we will start by taking a look at a community effort to collect a large bank of known and classified software vulnerabilities. This effort is called the Common Weakness Enumeration and is hosted by SANS Institute and MITRE Corporation and can be found at cwe.mitre.org. The database collects weaknesses from all over the software field, from huge server-side systems with Enterprise in their name, over client-side software all the way down to our end of the spectrum in the embedded space. This means that quite a few of the listed issues are not very relevant in our daily lives, but something very interesting unfolds if we look at the complementary list of the 25 software errors classified as most dangerous and the accompanying list of 15 runner ups compiled in 2011. Take a look at the following table:

This list might give anyone with at least a faint knowledge of C a slightly uneasy feeling; who hasn’t spent countless hours on chasing down the cause for a sudden memory corruption or the unexpected funny output value? The “interesting” thing with the C language is that the above problems (and then some) are more or less built into the language – For example, it’s perfectly legal to overflow or wrap-around an unsigned integer variable and often it’s the most efficient and convenient way to accomplish something, but sometimes this property of the language will bite us hard. Further, although it’s not legal to overflow a signed integer variable, a compiler will most likely emit fairly sensible code for an overflow anyway, at least as long optimizations are kept low or turned off. We might for example rely on the fact that assigning a larger signed type to a smaller signed type is OK as long as there is no overflow or truncation. The larger type might be part of a reusable API and we make the assumption that the values will never overflow our smaller type, but a few API revisions down the road this might no longer be true. The tricky thing is that an overflowed or truncated value we end up using can be a perfectly legal input value in our own code, so such an error might go unnoticed through testing since the code seems to behave correctly.
Pointers are another source of great joy and once again the language in itself does what it can to keep out of the way and allow us to shoot off feet and other extremities. The facts that we can coerce a pointer to point to essentially anything, can do more or less unbounded arithmetic on pointers and that basically the only form of access control we get is if the hardware generates an exception does not really help us in creating correct programs. Adding dynamic heap memory management to the mix make things even more interesting…
Chasing stray pointers can take literally forever, because a write through a bad pointer might affect data that is not even remotely associated with the program logic executing the write. Similar to reading truncated data, reading data from a bad location might not even trigger an error in testing if the data can be interpreted as valid or if the read in itself does not trigger a hardware exception.
Similar situations can arise when dealing with dynamically allocated memory where we might for example write to a block that we have already returned to the heap. Another part of the program might have allocated the same block or part of it and written something to it that it expects to read back at a later time.
Pointer and heap issues are especially insidious, since it can be perfectly enough with just one out-of-bounds write to bring the program into an unsafe state or open it up for external attacks. If you can for example trick a program into doing a buffer copy that overruns a fixed-size buffer on the stack you might use this to copy in a piece of malicious code on the stack and at the same time replace the correct return address with an address of your choosing. As seen in the table above, such attacks are a classic way to break a system and CWE-120 is actually the highest ranked weakness in the list that is not an SQL injection or OS command injection vulnerability.
On common ground
We have noted above that the trickier errors of these types are very good at surviving through both unit testing and integration testing. This is not really strange, since the bad behavior is often triggered by unexpected behavior at the external interfaces of the program combined with the fact that an erroneous situation might arise without wreaking any visible havoc in the system. In many projects testing is naturally driven by the functional specification, so emphasis is directed to the described use cases and associated scenarios. Further, creating negative tests that can provoke visible errors in the running system is often very hard work and time consuming. (Or something of a black art, depending on whom you ask.) It can really be an art to be able to step out of the comfort zone and design tests that has no other purpose than to crash or compromise the system instead of just confirming behavior for expected input.
What can be done to assist in finding issues like the ones discussed? The CWE issues we discussed above can be classified into three broad categories: arithmetic issues, bounds issues and heap checking.
Arithmetic issues
This category includes overflow, wraparound, conversion errors, division by zero and, oddly enough, missing default labels in switch statements. Such errors can be detected by inserting specific instrumentation code at all places where a potential error can happen. Source level instrumentation often insert an if-statement or equivalent that checks the condition and either print something to stdout or write a special value to a port to log the issue. Analogously, a compiler can insert instructions to check the condition and somehow report the issue at runtime. Checks like this, whether they are implemented in the source domain or in the compiler are relatively easy to perform and does not in general influence RAM requirements or stack depth. Code size will increase more or less linearly with the number of operations to check. For example, compiler-directed checking for division-by-zero amounts to no more than checking the divisor against 0 before performing the division, so the full check is essentially one instruction for the comparison and one or two instructions for jumping to some reporting code.
Bounds issues
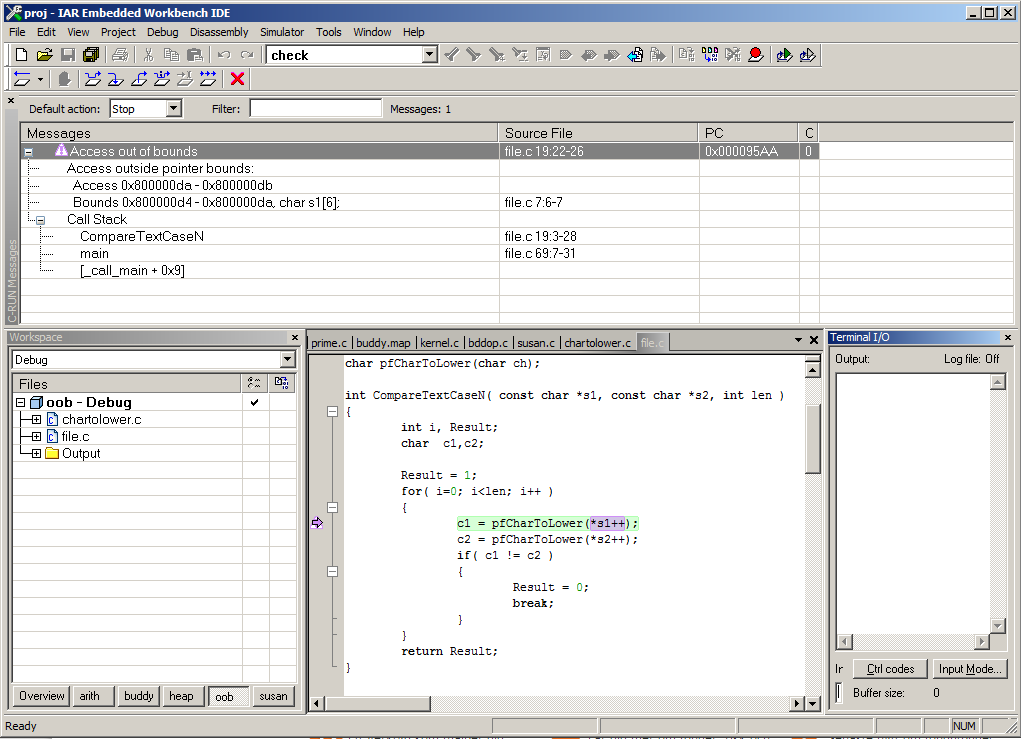
Bounds issues is a very broad category of problems that include typical out-of-bounds issues like writing or reading outside the defined bounds of an array. But the out-of-bounds concept can be generalized to deal with anything that is accessed through a pointer regardless of type or size. This includes things like pointers to scalar objects on the stack, so if you happen to change a pointer, or someone with malicious intent does it for you, to something on the stack, a state-of-the-art bounds checker can detect if the new value of the pointer is within the bounds of a valid object. This means not only keeping track of pointers, but also keeping track of valid ranges for objects that are pointed to.
Tracking pointers is not easy. It can be done on the source level, but really gains from being done by a compiler. As mentioned, a fast and reliable bounds check needs to keep track of pointers and associated ranges, as well as use this information at each read or write through anything that looks like a pointer. (Remember that C style arrays are nothing more than pointers with some fancy additional semantics!) Bounds checking will impact not only performance, but also code size and RAM requirements; the trick is in making it as small as possible!
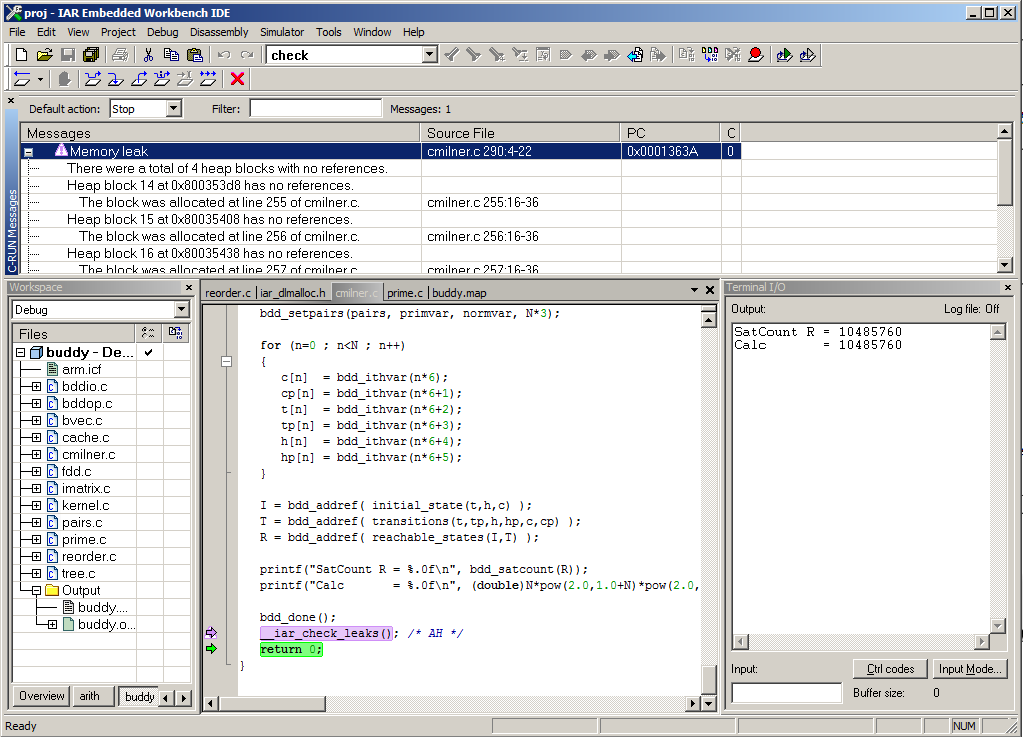
An additional complexity with bounds checking is how to deal with pointers that pass through interfaces to or from libraries only available in object form or assembly language. Such situations must invariably be addressed by the user, but differences in complexity and ease of use can be quite significant depending on what tool you’re using.
Heap checking
Heap checking is the art of checking that the heap retains its integrity and does not leak allocated blocks over time. Efficient heap checking is essentially an exercise in library implementation, but knowing the internals of the associated compiler can be beneficial if some functionality can be treated much the same way as other compiler intrinsic functions. Integrity checking is typically done on each call to malloc, free and their friends, both in the C and C++ world. However, a good heap checking package also enables detection of things like writing or reading from already freed memory blocks or writing outside the bounds of an allocated block. It can also mark certain memory blocks to not be part of leak detection or check leaks or heap integrity at arbitrary execution points as decided by the user. Heap integrity checking can be a real drag on performance if the heap is big, since the checks can entail traversing the full heap, so a way to decide the frequency of checks can be crucial for some applications.
Back to basics
So far, expect for the preamble, we haven’t really said anything about the product C-RUN for runtime analysis and error checking. Reading this far you might have guessed that C-RUN covers arithmetic checking, bounds checking and heap checking and you would be right. C-RUN is a separate product that you add on top of an existing IAR Embedded Workbench, or rather by upgrading the license to include C-RUN. C-RUN is available for IAR Embedded Workbench for ARM and RX and if you have a standard edition with a valid Support and Update Agreement you can easily evaluate C-RUN in size-limited mode.
So, how does C-RUN manifest itself for you as a user? As a very natural extension of our compiler and debugger technology I would say, but I might be biased. The typical use case merely involves setting the desired options, rebuilding the project and running it in the debugger to see if the checks identify any issues. The debugger will tell you in great detail exactly what went wrong and give you a call chain to see from where you came. The workflow is precisely that simple! No mucking about with integration issues, incompatible tool versions, learning a new parser how to ignore target specific keywords or finding include files and symbols etc. But doing full-scale integration tests with a debugger attached might not be feasible, you say, due to for example electrical isolation and separation. No worries, the default reporting mechanism is optimized for use in our debugger, but you can easily replace that mechanism with something that report issues in a manner that suits your environment, logging to memory or file, using printf or writing to a dedicated port for example.
C-RUN is designed to be a natural part of your day-to-day development workflow, no matter if you are working in a traditional edit/build/debug cycle, running unit tests or doing integration tests by not being in the way or requiring some magic hand waving to get going.
But in what way is compiler directed instrumentation different from source level instrumentation? On the surface it is more or less the same thing; the tool must insert instrumentation code at all interesting places, i.e. where something worth checking takes place. This can be an assignment that might overflow or a read through a pointer that might be out-of-bounds or something else. In practice there are some differences:
- The compiler knows the difference between application code and code needed for the runtime checks. Among other things this means that the compiler can first employ a battery of optimizations and then insert optimized instrumentation code on what’s left while still retaining the connections with the original source.
- When instrumenting on the source level, the instrumentation code is likely to break quite a lot of optimizations that would have been possible on the original code. This is essentially due to the same thing as above: the compiler has no idea that large parts of the code it looks at are special and can thus receive special treatment.
- Both the above bullets focus on optimizations, but in what way is that important? In the end the amount of code you have space for on target or the real time performance you need can determine what kinds of tests you can run on your production hardware and how many permutations of instrumented test builds you have to create and run. Worst case, with too much overhead from the instrumentation you might not be able to run any checked tests on hardware.
That being said, it might be so that a compiler optimizes the code in such ways that a potentially erroneous operation will not happen. And this might happen regardless of how the instrumentation was done. So given time and space it can be beneficial to also test with optimization levels that are lower than the ones used for production builds. - Integration with your build environment. This can be a headache, since the instrumentation tool essentially needs to have the same information about your code and build environment as your build tool chain. The tool also needs to support the same languages as your build tool. This sounds like a no-brainer, but given things like language extensions and different interpretations of the language standards it’s definitely not a given. Add complicated build dependencies, header file transparency and complex module and include hierarchies and it can be a mess to set up something that at the same time works for daily development. Some such tools want to own the whole build and test process, effectively introducing yet another IDE in your toolbox.
- Integration into the build tool chain means that it is very easy to set up one or more build configuration that includes parts or all of the C-RUN checks and switch between these configurations and the original build configuration.
Don’t get me wrong here. There are several state-of-the-art test and analysis tools on the market that can do some really wonderful stuff by operating on the source level, and C-RUN is in no way a replacement for these tools. However, these tools are mainly used in dedicated unit test, requirement validation and compliance scenarios, whereas we focus on the low-level, close-to-the-metal stuff. Through an easy-to-use interface, C-RUN provides you with extremely valuable feedback already as soon as the first iteration of code is about to be taken for a test drive. And thanks its tight integration into IAR Embedded Workbench, C-RUN can be part of the daily work for any developer.