시스템 신뢰성 확보를 위한 스택과 힙의 숙달
스택(stack)과 힙(heap)은 임베디드 개발에서 기본이 되는 개념입니다. 스택과 힙을 적절히 설정하는 것은 시스템의 안정성과 신뢰성에 있어 필수이며, 이것을 제대로 사용하지 않으면 시스템이 기상천외한 방식으로 큰 문제를 일으키게 됩니다.
스택과 힙 메모리는 반드시 정적으로, 프로그래머가 직접 할당해야 합니다. 아주 작은 임베디드 시스템을 제외하고 스택 공간의 계산은 어렵기로 악명이 높습니다. 그리고 스택의 이용량을 과소 계상하는 경우 심각한 런타임 에러를 초래할 수가 있으며, 이 에러를 찾는 것조차 어렵습니다. 반면 스택을 과다계상하는 경우에는 메모리의 낭비가 발생하게 됩니다. 최악 시나리오의 최대 스택 심도는 대부분의 임베디드 프로젝트에서 매우 유용한 정보입니다. 어플리케이션에서 필요로 하는 스택이 얼마인지를 산출하는 과정이 아주 쉬워지기 때문입니다. 힙 메모리는 정상적으로 오버플로우 하지만, 실제로 임베디드 어플리케이션은 이러한 극단적인 메모리 부족 상황에서 회복하는 것이 거의 불가능하기 때문에 실질적인 도움은 되지 않습니다.
간단하게 알아보는 스택과 힙
범위
이번 기사는 신뢰할 수 있는 스택 및 힙의 설계, 그리고 스택과 힙을 안전한 방식으로 최소화하는 방법에 대해 다룹니다.
데스크톱 시스템과 임베디드 시스템은 스택과 힙 설계 에러, 그리고 고려 사항에 있어 일부 유사한 점이 있습니다. 대부분의 측면에서는 크게 차이를 보이지만 말입니다. 이러한 환경의 차이로 들 수 있는 예의 하나가 바로 가용 메모리입니다. 윈도우스와 리눅스의 경우 기본 스택 공간은 1 ~ 8 Mbyte이며, 여기서 더 늘이는 것도 가능합니다. 힙 공간은 가용한 물리적 메모리 및/또는 페이지 파일 크기 내에서 무제한입니다. 반면 임베디드 시스템은 메모리 자원이 매우 제한되어 있습니다. 특히 RAM 공간의 경우 더욱 제약이 심합니다. 이렇게 메모리 제약이 따르는 환경의 경우 스택과 힙을 최소화해야 할 필요성이 분명히 존재합니다. 소형 임베디드 시스템의 경우, 공통적으로 가상 메모리 메커니즘이 존재하지 않는 것이 일반적입니다. 스택, 힙, 글로벌 데이터(즉 변수, TCP/IP, USB 버퍼 등)은 할당이 정적이며, 어플리케이션을 빌드 할 때에 할당이 발생합니다.
여기서는 소형 임베디드 시스템에서 발생하는 특수한 문제점을 다루어 볼 것입니다. 스택과 힙을 공격으로부터 방어하는 방법에 대해서는 다루지 않는 것으로 하겠습니다. 이것은 데스크톱 및 모바일 기기 분야에서 크게 문제가 되고 있는 부분으로, 임베디드 시스템의 위협이 될 가능성이 높습니다. 그리고 현재 위협이 되지 않는다고 해도, 앞으로는 그렇게 될 가능성이 높다고 하겠스니다.
한계의 초월
우리의 현실 생활에서 한계를 뛰어 넘는다면 칭찬을 듣겠지만, 문제가 발생할 수도 있습니다. 프로그래밍에서 데이터 할당과 관련해 한계를 뛰어 넘어 버리는 경우에는 반드시 곤란한 상황에 처하게 됩니다. 문제가 직접적으로 발생하거나, 시스템 테스팅 중에 나타난다면 차라리 다행이겠으나, 고치기에는 너무 늦은 상태, 이미 수 천개의 제품이 고객에게 배송된 후이거나, 원격지에 설치한 다음에 발견되는 경우도 있을 수가 있습니다.
할당된 데이터의 오버플로우는 3 가지 저장 구역, 즉 글로벌, 스택, 힙 메모리에서 발생할 수가 있습니다. 행렬이나 포인터 참조에 써넣기를 하는 경우, 오브젝트에 할당된 메모리 외부에서 접근이 일어나는 원인이 될 수가 있습니다. 일부 행렬은 정적 분석으로 접근을 검증할 수가 있습니다. 예를 들어, MISRA C 체커 또는 컴파일러가 이러한 역할을 수행할 수가 있습니다.
int array[32];
array[35] = 0x1234;행렬 인덱스가 가변 표현형(variable expression)인 경우, 정적 분석 만으로는 모든 문제를 발견해 내지 못합니다. 포인터 참조 역시 정적 분석으로는 추적에 어려움이 있을 수 있습니다:
int* p = malloc(32 * sizeof(int));
p += 35;
*p = 0x1234;오버플로우 에러를 잡아내기 위한 런타임 방식은 오래 전부터 데스크톱 시스템에서 사용되어 왔습니다. Purity, Insure++, Valgrind 등이 여기에 해당됩니다. 이들 도구는 런타임에서 메모리 참조의 유효성 검증을 위한 어플리케이션 코드의 계측을 통해 사용할 수가 있습니다. 단, 이를 위해서는 어플리케이션 실행 속도가 극적으로 느려지게 되며, 코드의 용량도 증가합니다. 그러므로 소형의 임베디드 시스템에서는 사용하기 어렵습니다.
스택
스택은 프로그램에서 다음과 같은 항목을 저장하는 메모리 상의 구역을 말합니다.
- 로컬 변수
- 리턴 어드레스
- 함수 아규먼트(arguments)
- 컴파일러 임시 파일
- 간섭 컨텍스트
스택 상의 변수는 함수의 지속 기간 동안만 존재할 수가 있습니다. 함수의 리턴이 일어나는 즉시 사용된 스택 메모리는 해방되어, 이후 이루어지는 함수 호출 시 사용이 가능해집니다.
스택 메모리는 프로그래머가 정적으로 할당해야만 합니다. 스택은 통상적으로 메모리 내에서 하방으로 성장하며, 스택을 위해 할당된 메모리 구역의 크기가 모자란 경우, 스택 아래에 할당된 구역에 실행 코드를 쓰게 되며, 오버플로우 상황이 발생하게 됩니다. 쓰기가 이루어진 구역은 통상적으로 글로벌 및 정적 변수가 저장되는 곳입니다. 그러므로 스택 이용량을 과소 계상하는 경우 변수 오버라이팅, 와일드 포인터, 리턴 어드레스 오염 등 심각한 런타임 에러가 발생할 수가 있습니다. 이러한 에러는 하나같이 발견해 내는 것이 어렵습니다. 반면 스택을 과다계상하는 경우에는 메모리의 낭비가 발생하게 됩니다.
여기서는 안심하고 필요한 스택 용량을 계산하고, 스택과 관련한 문제점을 탐지할 수 있는 방법을 알아보겠습니다.
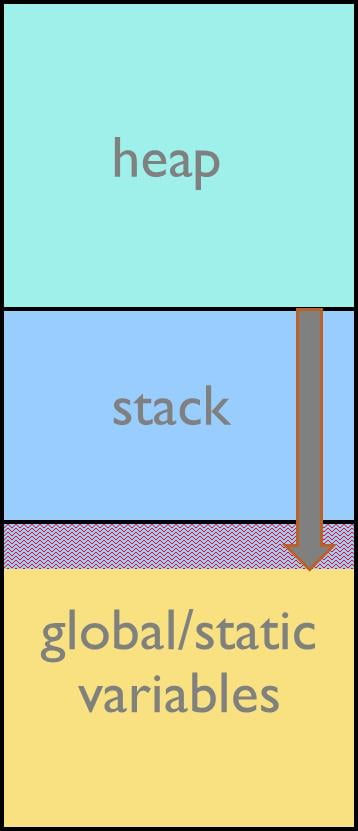
그림 1: 스택 오버플로우 상황
힙
힙은 시스템의 동적 메모리가 위치하는 곳입니다. 동적 메모리 및 힙은 대부분의 소형 임베디드 시스템에서는 필수적으로 요구되는 되지는 않습니다. 동적 메모리는 서로 다른 프로그램간에 메모리 공유를 가능하게 해 줍니다. 하나의 모듈에 더 이상 메모리를 할당할 필요가 없는 경우, 메모리를 메모리 할당자에게 반납하여, 다른 모듈에서 사용할 수 있도록 해 주는 것입니다.
힙에 저장하는 데이터의 예로는 다음을 들 수가 있습니다.
- 일시적 데이터 오브젝트
- C++ new/delete
- C++ STL 컨테이너
- C++ 예외
힙 공간 범위의 계산은 대규모 시스템의 경우 매우 어렵거나 불가능한 수준입니다. 왜냐하면 어플리케이션 자체가 동적인 성격을 지니기 때문이지요. 뿐만 아니라 임베디드 시스템에서는 힙 활용도를 측정하기 위한 도구가 많지 않지 않습니다. 하지만, 뒤에서 일부 가능한 방법에 대해 이야기해 보도록 하겠습니다.
힙의 무결성을 유지하는 것이 중요하지요. 할당된 데이터 공간은 통상적으로 핵심적인 메모리 할당기 하우스키핑 데이터와 뒤섞여 있습니다. 할당된 데이터 공간을 잘못 활용할 경우, 다른 데이터 공간이 오염될 위험은 물론이려니와, 전체 메모리 할당기의 오염은 물론, 어플리케이션 자체가 다운될 가능성이 매우 높습니다. 힙 무결성을 체크할 수 있는 몇 가지 방법에 대해서는 뒤에 살펴보도록 하겠습니다.
또 한가지 생각해 봐야 하는 부분은 힙의 실시간 성능이 반드시 정해져 있는대로 나타나는 것은 아니라는 점이비다. 이전의 이용량, 그리고 요청된 데이터 공간 용량 등의 요인에 따라 메모리 할당 시간이 정해지는 것입니다. 이는 사이클을 기반으로 하고 있는 임베디드 개발자라면 반드시 피하고 싶은 상황일 것입니다.
비록 이번 기사는 힙에 대한 내용을 주로 다루고 있지만, 일반적으로 소형 임베디드 시스템에서는 가급적 힙의 사용량은 최소화하는 것이 바람직합니다.
스택 설계의 신뢰성
스택의 계산은 왜 그렇게 어려운가?
최대 스택 이용량의 계산을 어렵게 하는 요인에는 여러가지가 있습니다. 어플리케이션은 복잡한 것이 많고, 이벤트를 기반으로 하는 것도 그 수가 상당합니다. 이들은 수 백 개의 함수와 간섭으로 구성됩니다. 임의의 시간에 발동되는 간섭 함수가 존재할 가능성이 높으며, 이들을 내재설계(nest)하는 것이 가능할 경우, 상황을 파악하는 것은 더 힘들어 집니다. 이것은 손쉽게 파악해 낼 수 있는 자연스러운 실행의 흐름이 존재하지 않는 것을 의미합니다. 함수 포인터를 사용한 간접적인 호출이 이루어질 수도 있습니다. 이 경우 호출의 목적지가 될 수 있는 함수는 그 수가 매우 많으며, 순환 및 무주석 어셈블리 루틴 역시 최대 스택 사용량을 계산하는 데에 있어 문제를 불러 일으킵니다.
시스템 스택이나 사용자 스택 등 복수의 스택을 구현하고 있는 마이크로컨트롤러는 그 수가 많습니다. µC/OS, ThreadX 등의 임베디드 RTOS를 사용하는 경우에도 복수 스택을 구현하는 것이 가능하며, 여기서는 각각의 스택이 자기만의 스택 구역을 지니게 됩니다. 런타임 라이브러리 및 외부 소프트웨어 역시 계산을 어렵게 하는 요인이 되는데, 이는 라이브러리 소스 코드 및 RTOS를 찾기가 어렵기 때문이기도 합니다. 여기서 또 한가지 기억해야 하는 사실은 어플리케이션 코드 및 스케줄링의 변동은 스택 이용량에 있어 상당한 영향을 미칠 수 있다는 점입니다. 컴파일러의 종류를 달리 하거나, 최적화 수준을 바꾸는 경우에도 코드가 달라지기 때문에 스택의 이용량이 변하게 됩니다. 이러한 여러 요인에 따라 최대 스택 요구량을 지속적으로 추적하는 것이 중요해지는 것입니다.
스택 사이즈 설정 방법
어플리케이션을 설계할 때에 고려해야 하는 중요 조건 중의 하나가 바로 필요 스택 용량입니다. 또, 필요로 하는 스택의 양을 결정짓기 위한 방법도 필요합니다. 남아 있는 모든 RAM 용량을 스택 용도로 돌린다고 하더라도, 그것으로 충분할 지 어떨지는 장담할 수가 없습니다. 한 가지 바로 생각해 볼 수 있는 방법은 최악의 스택 이용 양상을 도출하는 상황을 상정하여 시스템을 시험하는 것입니다. 이러한 시험을 진행하는 과정에서는 얼마나 많은 스택을 이용해야 할지 알아내기 위한 방법이 필요합니다. 이것을 해결하는 방법은 기본적으로 두 가지가 있습니다. 하나는 현재의 스택 이용량을 printout 하는 것이고, 나머지 하나는 메모리 내 스택의 이용시, 테스트 실행이 종료된 다음에 반드시 흔적이 남게 하는 것입니다. 그러나 앞서 설명한 바와 같이, 대부분의 복합적인 시스템에서 최악 조건을 불러 일으키는 것은 매우 어렵습니다. 다수의 간섭을 지니는 이벤트 기반 시스템을 테스트하는 과정의 근본적인 문제점은 반드시 시험과정에서 누락되는 실행 경로가 발생된다는 점입니다.
또 다른 접근법은 이론적으로 최대 스택 필요량을 계산하는 것입니다. 전체 시스템의 요구량을 수기로 계산하는 것이 불가능하다는 사실은 쉽게 짐작할 수가 있습니다. 이러한 계산을 위해서는 전체 시스템을 분석할 수가 있는 툴이 필요합니다. 이러한 툴은 바이너리 이미지 또는 소스 코드 상에서 실행이 이루어질 수 있어야 합니다. 바이너리 툴은 기계 명령어 단위에서 실행되며 개발자의 코드를 통해 프로그램 카운터의 가능한 모든 행동을 찾아 냅니다. 그리고 이를 통해 최악 시나리오의 실행 경로를 발견해 냅니다. 소스 코드 정적 분석 툴의 경우는 안에 포함되는 모든 컴필레이션(compilation unit)을 읽어 냅니다. 이 두가지 경우 모두 툴은 컴필레이션 단위 내에서 직접적인 함수 호출 및 포인터를 통한 간접적 함수 호출을 판정해 낼 수가 있어야 하며, 동시에 모든 호출 그래프에 대해 전체 시스템에 걸친 스택 사용 프로필을 보수적으로 산정할 수 있어야 합니다. 소스 코드 툴 역시 할당 및 컴파일러 임시 파일(temporaries) 등 컴파일러가 스택 상에 부과하는 수요량을 파악할 필요가 있습니다.
이러한 종류의 툴을 직접 작성하는 것은 어려운 일입니다. 하지만 이를 대신할 수 있는 시판 제품들이 존재합니다. 이러한 제품들은 단독형 정적 스택 계산툴에서부터 스택 계산 툴 등 솔루션 벤더가 제공하는 것들까지 다양합니다. 후자의 경우는 Express Logic의 ThreadX RTOS를 예로 들 수가 있습니다. 최대 스택 요구량을 계산하는 데에 필요한 정보를 지니고 있는 또 다른 종류의 툴로 컴파일러 및 링커를 들 수 있습니다. 예를 들어 IAR Embedded Workbench for ARM 역시 이러한 기능을 제공합니다. 지금부터는 스택 용량 요구량을 계산하는 데에 사용할 수 있는 방법들을 일부 살펴보도록 하겠습니다.
스택 사이즈 설정 방법
스택의 심도를 계산하는 또 하나의 방법은 현재 스택 포인터의 어드레스를 쓰는 것입니다. 이것은 함수의 아규먼트나 로컬 변수의 어드레스를 취하는 방식을 통해 가능합니다. 만일이 메인 함수의 시작 부분에 이러한 작업을 수행하거나, 가장 많은 스택을 사용한다고 생각하는 각각의 함수에 대해 실행하는 경우, 어플리케이션이 필요로 하는 스택의 양을 계산할 수가 있습니다. 아래는 스택이 높은 위치의 어드레스에서 낮은 위치의 어드레스로 확장해 나가는 경우를 상정한 예시입니다.
char *highStack, *lowStack;
int main(int argc, char *argv[])
{
highStack = (char *)&argc;
// ...
printf("Current stack usage: %d\n", highStack - lowStack);
}void deepest_stack_path_function(void)
{
int a;
lowStack = (char *)&a;
// ...
}이것은 소형의 시스템, 그리고 결정론적 구조의 시스템에서는 아주 높은 효과를 발휘하는 방법입니다. 그러나 가장 깊은 스택 심도를 지녀, 최악 상황을 일으킬 수 있는 내재 함수를 파악해 내는 것은 상당수의 경우 쉬운 일이 아닙니다.
여기서 한 가지 기억해야 하는 부분은 이러한 방식을 통하여 도출되는 결과는 간섭 함수(interrupt functions)의 스택 이용량은 계산에 넣지 않는다는 것입니다.
이를 응용한 방법으로 높은 주파수로 정기적으로 타이머 간섭을 사용해 스택 포인터를 샘플링하는 방법도 있습니다. 간섭의 주파수는 가급적 어플리케이션의 실시간 성능에 영향을 미치지 않는 범위 내에서 높게 잡습니다. 통상적으로 설정되는 주파수의 범위는 10-250 kHz입니다. 이러한 방법은 가장 깊은 심도의 스택 이용량을 보이는 함수를 수작업으로 찾지 않아도 된다는 점에서 유리합니다. 또한 샘플링 간섭이 다른 간섭을 차단할 수가 있는 경우, 간섭 함수를 통하여 스택 사용량을 얻어내는 방법도 있습니다. 그러나 간섭 함수는 그 지속 기간이 매우 짧으며, 샘플링 간섭이 이를 놓칠 수도 있으니 주의해야 합니다.
void sampling_timer_interrupt_handler(void)
{
char* currentStack;
int a;
currentStack = (char *)&a;
if (currentStack < lowStack) lowStack = currentStack;
}스택 가드존
스택 가드존은 메모리 구역 중에서 스택 바로 아래에 위치하는 곳으로, 스택이 오버플로우 할 시 흔적이 남는 구역입니다. 이러한 방식은 운영 체제가 스택오버플로우 상황에서 손쉽게 메모리 보호 에러를 탐지해 낼 수가 있는 데스크톱 시스템에서는 항상 사용하고 있는 것입니다. MMU가 없는 소형의 임베디드 시스템에서도 가드존을 삽입하는 것이 가능하며, 이를 사용할 시 매우 편리합니다. 가드존이 위력을 발휘하기 위해서는 어느 정도 적당히 큰 사이즈를 지녀, 가드존으로 내려오는 쓰기 데이터를 받아 낼 수가 있어야 합니다.
가드존의 연속성은 정기적으로 가드존 채움 패턴이 적절히 유지되고 있는지를 소프트웨어를 통해 확인하는 방식으로 점검할 수가 있습니다.
MCU에 메모리 보호 유닛이 장비되어 있는 경우, 이보다 더 나은 방법이 있습니다. 이 경우 메모리 보호 유닛이 가드존에 쓰기 시도가 이루어질 경우 발동하도록 설정할 수가 있는데, 접근이 일어날 시에는 에러가 발동하여 예외 핸들러가 발생한 사태를 기록, 나중에 분석할 수가 있습니다.
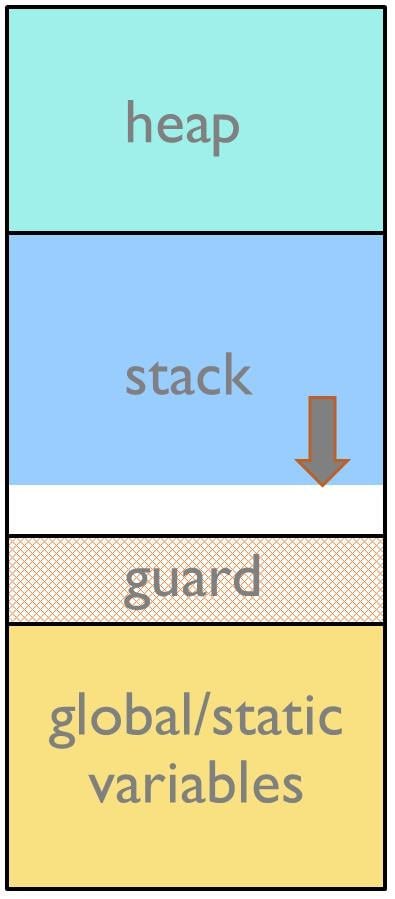
그림 2: 가드존을 포함하는 스택
전용 패턴으로 스택 구역 채우기
스택 오버플로우를 탐지하는 기법 중의 하나로, 어플리케이션의 실행이 이루어지기 전, 당된 전체 메모리를 별도의 채움값으로 채워버리는 방법이 있습니다. 0xCD 등이 이러한 채움값으로 사용될 수가 있습니다. 실행이 중지될 때마다 스택의 맨 끝에서부터 위로 올라가며 0xCD이 아닌 값이 발견될 때까지 를 검색해 나갈 수가 있습니다. 이렇게 다른 값이 발견되는 지점까지 스택이 사용된 것으로 보는 것입니다. 만일이 해당 지정값이 보이지 않는 경우에는 메모리 오버플로우가 일어났다고 보면 됩니다.
비록 이것은 스택 사용량을 추적할 수 있는, 합리적으로 신뢰할 수 있는 방법이지만, 그럼에도 스택 오버플로우가 반드시 탐지된다는 보장은 없습니다. 예를 들어 스택이 의도와는 달리 경계 외부로 계속 성장해 나갈 수가 있고, 스택 범위에 인접한 바이트는 실제로 손을 대지 않으면서 스택 구역 외부의 메모리까지도 수정해 버리는 결과가 발생할 수가 있습니다. 마찬가지로, 어플리케이션 차원에서 실수로 스택 구역 내의 메모리를 수정해 버릴 수도 있습니다.
이러한 스택 이용량 모니터링 방법은 디버거에서 흔히 쓰는 방식입니다. 그것은 그림 3에서 보이는 바와 같이 디버거 차원에서 시각적으로 스택 이용량을 보여줄 수 있다는 것을 의미합니다. 디버거는 스택 오버플로우가 발생하는 즉시 이를 탐지해 내지는 못하며, 스택 오버플로우가 남기는 흔적을 탐지할 뿐입니다.
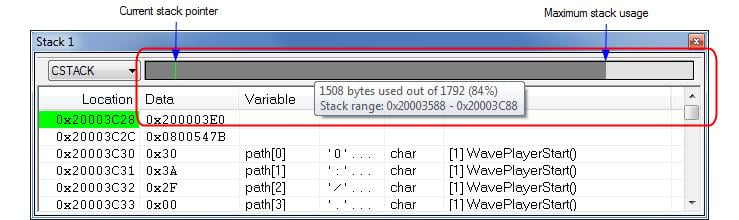
그림 3: IAR Embedded Workbench 내의 스택 창
링커 계산 최대 스택 요구량
이번에는 컴파일러나 링커와 같은 빌드툴이 최대 스택 요구량을 어떻게 계산하는지를 알아보겠습니다. 여기서는 예시로서 IAR 컴파일러 및 링커를 사용합니다. 컴파일러는 필요한 정보를 생성하며, 상황이 맞을 시에는 링커가 정확하게 최대 스택 이용량을 각각의 호출 그래프 부리 부분에 대해 계산해 낼 수가 있습니다. (다른 함수로부터 호출이 이루어지지 않은 각각의 함수, 어플리케이션 개시 시점과 유사). 이 방법으로 정확한 측정을 해 내기 위해서는 어플리케이션 내의 각각의 함수가 사용하는 스택의 이용량을 정확하게 파악하고 있어야 합니다.
일반적으로, 컴파일러는 각각의 C 함수에 대해 이러한 정보를 생성하지만, 일부 상황에 따라서는 스택 과년 정보를 시스템에 직접 제공해 주어야 할 수도 있습니다. 예를 들어서 어플리케이션 내에서 간접 호출이 이루어진다고 할 경우(함수의 포인터를 이용한 호출), 각각의 호출 함수를 통하여 호출이 가능한 함수를 담은 목록을 제공해야 합니다. 이것은 소스파일 내에서 pragma directives를 사용하는 방식으로 이루어질 수가 있습니다. 또는 링크 시에 별도의 스택 이용량 제어 파일을 사용하는 방법도 있습니다.
void
foo(int i)
{
#pragma calls = fun1, fun2, fun3
func_arr[i]();
}만일에 스택 이용량 제어 파일을 사용하는 경우에는 스택 이용량 정보를 스틱 이용량 정보가 없는 모듈 내의 함수에 대해 제공할 수가 있습니다. 링커는 일부 필요한 정보가 누락되어 있는 경우 경보를 발동 시킬 수가 있습니다. 예를 들어 다음과 같은 상황이 발동의 조건이 될 수가 있습니다.
- 스택 이용량 정보를 지니고 있지 않은 함수가 최소한 하나 이상 존재한다.
- 어플리케이션 내에 발생 가능한 호출 함수의 목록에 제공되지 않는, 간접 호출 위치가 최소 1 개 이상 존재한다.
- 알려진 간접 호출이 발생한 바는 없으나 호출 그래프 루트에는 알려져 있지 않은 미호출 함수가 최소 하나 이상 존재한다.
- 어플리케이션 내에 순환(recursion)(호출 그래프 내의 사이클)이 포함되어 있다.
- 호출 그래프 루트로 선언된 함수에 대한 호출이 발생하였다.
스택 이용량 분석 기능이 활성화되어 있는 경우, 스택 사용량 챕터를 링커 맵 파일에 추가하는 것이 가능해 집니다. 이러한 파일에서는 각각의 호출 그래프 루트에 대해서 최대 스택 심도에 도달하는 구체적인 콜 체인의 목록을 제시합니다.

전체 시스템에 대한 총 최대 스택 이용량은 각각의 호출 그래프 루트에 대한 결과값을 더하여 산출합니다. 여기 분석에서는 최대 가능 스택 이용량이 500+24+24+12+92+8+1144+8+24+32+152 = 2020 byte 가 됩니다.
여기서 한 가지 반드시 기억해야 하는 것은 이러한 종류의 스택 이용량 분석은 최악의 상황에 대응하는 결과를 도출한다는 것입니다. 어플리케이션은 실제로는 최대 콜 체인 내에 나타나지 않을 수도 있습니다. 이는 설계를 통해서 방지할 수도 있고, 우연에 의한 결과일 수도 있습니다.
신뢰할 수 있는 힙 설계
발생 가능한 문제는?
힙 이용량을 과소 계상하게 되면 malloc()에서 out of memory error가 발생할 수가 있습니다. 이는 malloc()의 리턴 상태를 확인함으로써 손쉽게 탐지가 가능하지만, 이렇게 되면 이미 늦어버린 것입니다. 이것은 매우 심각한 상황이라고 할 수가 있습니다. 왜냐하면 대부분의 시스템에서 적절한 회복 방안이 더 이상 존재하지 않기 때문입니다. 유일한 대응책은 어플리케이션을 재시작 하는 것 뿐입니다. 힙의 동적인 특성 상 어느 정도 힙 이용량을 과다 계상하는 것도 필요합니다. 그러나 지나치게 여유분을 크게 잡는 경우에는 메모리 자원의 낭비로 이어질 수가 있습니다.
힙 사용 시 발생할 수 있는 장애 요인으로, 다음과 같은 두 가지를 추가로 생각해 볼 수가 있습니다.
- 힙 데이터 덮어쓰기(변수 및 포인터)
- 힙의 내부 구조 손상
여기서는 계속하기에 앞서, 동적 메모리 API를 복기해 보도록 하겠습니다.
void* malloc(size_t size);- 할당 용량 바이트
- 할당된 메모리 블록에 포인터 반환.
- 메모리 블록을 클리어 하지 않음.
- 메모리가 더 이상 남아 있지 않은 경우 NULL 반환.
free (void* p);- p가 지정하는 메모리 공간 해방 (frees)
- malloc(), calloc(), 또는 realloc()를 이전에 호출한 결과 p가 반환되었어야 함.
- free(p)를 2회 이상, 동일한 p에 대해 호출하지 말 것.
void* calloc(size_t nelem, size_t elsize);- malloc()와 유사.
- 메모리 블록 클리어.
void* realloc(void* p, size_t size);- malloc()와 유사.
- 이전에 할당된 블록을 확대/축소
- 반환된 블록은 반드시 새로운 어드레스를 지녀야 함.
C++- new 연산자 - malloc()과 유사.
- new[]
- delete 연산자 - free()와 유사.
- delete[]
동적 메모리 할당기의 구현은 다양한 방식으로 이루어질 수가 있습니다. 최근 가장 많이 사용되는 것이 Dlmalloc(Doug Lea’s Memory Allocator) 입니다. Dlmalloc은 Linux를 비롯하여, 여러 임베디드 시스템 용 개발툴에서 발견됩니다. Dlmalloc는 일반에 공개되어 있으며, 무료로 사용이 가능합니다.
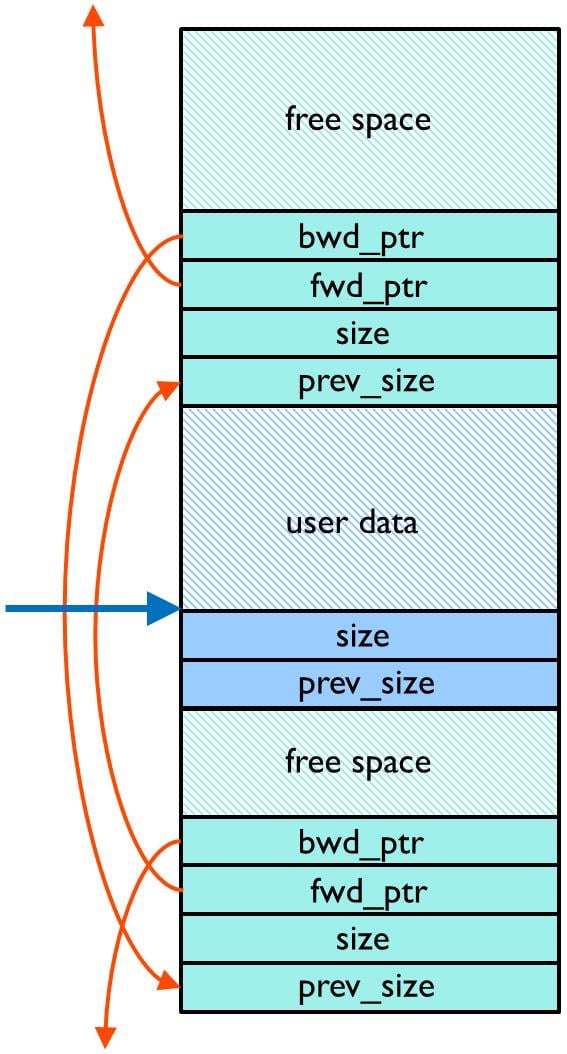
힙의 내부 구조는 어플리케이션에서 할당하는 데이터가 뒤섞여 있는 양상을 보입니다. 만일 할당된 내용을 할당된 데이터 외부에 쓰는 경우, 힙의 내부구조가 쉽게 손상될 수가 있습니다.
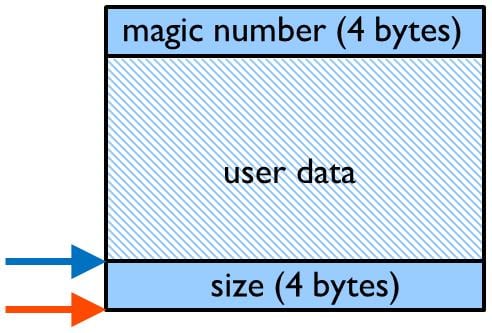
그림 5에서는 할당된 유저 데이터 주변의 다양한 데이터 구조를 간략하게 보여주고 있습니다. 그림 5를 보면 어플리케이션이 할당된 사용자 데이터 외부에 쓰기를 하는 경우 힙이 심하게 손상됨을 잘 보여주고 있습니다.
힙에서 필요로 하고 있는 메모리의 양을 계산하는 것은 결코 간단한 작업이 아닙니다. 대부분의 디자이너들은 이와 관련해 시행착오를 겪는 방법을 선택하는 경향이 있습니다. 그렇지 않을 경우 너무나 손이 많이 가기 때문입니다. 일반적으로 사용하는 알고리즘은 어플리케이션이 구동할 수 있는 가장 작은 힙을 찾아 낸 다음, 여기에 50%의 메모리를 추가하는 것입니다.
힙 에러 방지
출시 제품에 힙 에러가 섞여 들어가는 것을 방지하기 위해서는 다음과 같이 흔히 발생하는 에러에 대해 프로그래머 및 코드 리뷰어가 주의를 기울일 필요가 있습니다.
- 초기화 실수
초기화 하지 않은 글로벌 데이터는 항상 0으로 초기화 됩니다. 이러한 사실이 워낙 널리 알려져있다보니, 힙에서도 같은 방식이 적용될 것이라고 생각하는 경우가 많습니다. Malloc(), realloc() 및 C++ new는 할당된 데이터를 초기화 하지 않습니다. malloc() calledcalloc()은 할당된 데이터를 0으로 초기화하는 특수한 변수를 지닙니다. C++ new에서는 적절한 컨스트럭터를 호출하므로 모든 항목이 초기화 될 수 있도록 반드시 확인하십시오. - 스칼라와 행렬 구분 실패
C++에서는 스칼라와 행렬에 대해 사용하는 연산자(operator)가 틀립니다. 스칼라의 경우는 new와 delete를 사용하며, 행렬에서는 new[]와 delete[]을 씁니다. - 이미 해방(freed)된 메모리에 쓰기
이것은 내부 메모리할당자 데이터 구조에 손상을 가하거나, 이후 적절하게 할당된 데이터를 대상으로 하는 쓰기 동작으로 덮어쓰기가 될 수가 있습니다. 양측 모두 실제로 에러를 발견해 내는 것은 매우 어렵습니다. - 리턴값확인 실패
malloc(), realloc(), calloc()은 모두 메모리를 모두 소진해 버렸다는 의미로 NULL 포인터를 반환합니다. 데스크탑 시스템이라면 메모리 장애 및 out-of-memory 상태가 발동됩니다. 따라서 개발 과정에서 이를 발견해 내는 것이 용이합니다. 임베디드 시스템에서는 제로 어드레스 상에 flash가 있을 수가 있으며, 좀 더 눈에 덜 띄는 에러와 함께 생존할 가능성이 있습니다. 만일 MCU 상에 메모리 보호 유닛이 포함되어 있는 경우, 메모리 보호 장애(fault)를 flash 및 다른 실행 전용 구역에 대한 쓰기 접근 시 생성시키도록 설정하는 것도 가능합니다. - 동일한 메모리에 대해 여러 번 해방 처리
이것은 내부 메모리할당자 구조에 손상을 가할 가능성이 높으며, 탐지가 매우 어렵습니다. - 할당 구역 외부에 쓰기
이 경우 내부 메모리할당기 데이터 구조에 손상이 발생할 가능성이 매우 높으며, 탐지가 어렵습니다.
마지막 3 개의 에러는 malloc(), free() 및 관련 함수 주변에 wrapper를 둘 경우 아주 쉽게 탐지가 가능합니다. wrapper는 수 byte의 메모리를 추가로 할당하여 일관성 체크 시 저장해야 하는 추가 정보를 수용할 수 있도록 합니다. 예시 wrapper 내의 데이터 레이아웃은 그림 6에서 보이는 바와 같습니다. 맨 위의 ‘magic number’는 손상을 탐지하기 위해서 사용하며, 데이터 할당이 제거될 때에 확인합니다. 데이터 아래의 용량 란은 thefree() wrapper에서 사용하는 것으로, ‘magic number’를 찾기 위한 목적을 지닙니다. 이 wrapper 예시에서는 8 byte의 여유 용량을 매 할당 시 마다 제공합니다. 대부분의 어플리케이션에서는 이 정도의 양이면 적당합니다. 또한 이 예시는 C++ new 및 delete 연산자를 글로벌 범위에서 오버라이드하는 방법을 보여주고 있습니다. 여기서는 어느 시점에서 할당된 모든 메모리 역시 해방이 이루어질 경우에만 이러한 에러를 탐지하게 됩니다. 하지만 이와 같이 작동하지 않는 어플리케이션도 있을 수 있습니다. 그런 경우에는 wrapper 내에 모든 메모리 할당을 담은 리스트(list)가 있어야 하며, 해당 할당 리스트 상에 기록되어 있는 모든 할당 내역을 정기적으로 검증해야 합니다. 이를 구현하기 위한 여유분(overhead)는 생각처럼 크지 않을 수도 있습니다. 대부분의 임베디드 시스템은 동적 메모리의 사용량이 상대적으로 적기 때문입니다. 따라서 할당 리스트는 적당한 한도를 넘지 않습니다.
#include <stdint.h>
#include <stdlib.h>
#define MAGIC_NUMBER 0xefdcba98
uint32_t myMallocMaxMem;
void* MyMalloc(size_t bytes)
{
uint8_t *p, *p_end;
static uint8_t* mLow = (uint8_t*)0xffffffff; /* lowest address
returned by
malloc() */
static uint8_t* mHigh; /* highest address + data returned by
malloc() */
bytes = (bytes + 3) & ~3; /* ensure alignment for magic number */
p = (uint8_t*)malloc(bytes + 8); /* add 2x32-bit for size and magic
number */
if (p == NULL)
{
abort(); /* out of memory */
}
*((uint32_t*)p) = bytes; /* remember size */
*((uint32_t*)(p + 4 + bytes)) = MAGIC_NUMBER; /* write magic number
after
user allocation */
/* crude method of estimating maximum used size since application
start */
if (p < mLow) mLow = p;
p_end = p + bytes + 8;
if (p_end > mHigh) mHigh = p_end;
myMallocMaxMem = mHigh - mLow;
return p + 4; /* allocated area starts after size */
}
void MyFree(void* vp)
{
uint8_t* p = (uint8_t*)vp - 4;
int bytes = *((uint32_t*)p);
/* check that magic number is not corrupted */
if (*((uint32_t*)(p + 4 + bytes)) != MAGIC_NUMBER)
{
abort(); /* error: data overflow or freeing already freed memory */
}
*((uint32_t*)(p + 4 + bytes)) = 0; /* remove magic number to be
able to
detect freeing already freed memory */
free(p);
}
#ifdef __cplusplus
// global override of operator new, delete, new[] and delete[]
void* operator new (size_t bytes) { return MyMalloc(bytes); }
void operator delete (void *p) { MyFree(p); }
#endif힙 사이즈 설정 방법
어플리케이션에서 필요로 하는 최소 힙 사이즈는 어떻게 알아낼 수가 있을까요? 동적 행동 및 분절화가 발생할 수가 있는 관계로 그 답은 결코 쉽게 찾을 수가 없습니다. 여기서 권장되고 있는 접근법의 하나는 강제로 최대한 많은 동적 메모리를 사용하도록 설계된 시스템 테스트 시나리오에 따라 어플리케이션을 실행하는 것입니다. 여기서 한 가지 중요한 것은 낮은 메모리 이용량으로부터 반복적으로 전환하는 동작을 취해야 한다는 것입니다. 그렇게 해서 분절화(fragmentation)로 인해 발생할 수 있는 영향을 가늠합니다. 시나리오 테스트가 종료된 후, 힙의 최대 이용량 수준을 실제 힙 용량과 비교합니다. 어플리케이션의 성격에 따라 25-100%의 여유분을 두어야 합니다.
sbrk()을 통하여 데스크톱을 에뮬레이션 하는 시스템의 경우, malloc_max_footprint()을 통해서 힙 용량을 알 수가 있습니다.
sbrk() 에뮬레이션을 하지 않는 임베디드 시스템의 경우, 하나의 덩어리로 전체 힙을 메모리 할당기에 던져주는 것이 보통입니다. 이 경우 malloc_max_footprint()는 쓸모가 없어집니다. 그저 전체 힙의 크기만을 리턴하니까요. 이를 해결하는 방법의 하나가 바로, 예를 들어 아까 말씀드린 wrapper 함수 내에서, malloc()을 호출하고 나서 항상 mallinfo()를 호출하는 것입니다. 그리고 나서 전체 할당 공간을 관측하는 것이지요(mallinfo->uordblks). Mallinfo()는 연산량이 많습니다. 따라서 성능에 영향을 미치게 됩니다. 이보다 더 나은 방법은 할당된 구역 간의 최대 거리를 기록하는 것입니다. 이는 전혀 어렵지 않은 방법으로 wrapper 예시에서 보이고 있습니다. 최대값은 변수 myMallocMaxMem에 기록되고 있으니까요. 이러한 방법은 힙이 하나의 연속되는 메모리 구역을 차지하고 있을 때에 사용이 가능합니다.
결론
적절한 스택과 힙 구역을 설정하는 것은 임베디드 시스템의 안전성과 신뢰성을 확보하는 데에 있어 중요한 의미를 지닙니다. 스택과 힙 요구 사항 계산이 복잡하고 어려운 작업이기는 하지만, 이를 위해 활용이 가능한 다양한 도구와 방법이 존재합니다. 개발 단계에서 적절한 연산을 하는 데에 투입되는 돈과 시간은 일단 시스템의 전개가 이루어진 후에 스택 오버라이팅 문제를 일일이 찾아 헤메지 않아도 된다는 측면에서 충분한 보상을 받을 수 있을 것입니다.
참고문헌
- Nigel Jones, blog posts at embeddedgurus.com, 2007 and 2009
- John Regehr ,“Say no to stack overflow”, EE Times Design, 2004
- Carnegie Mellon University , “Secure Coding in C and C++, Module 4, Dynamic Memory Management”, 2010