セキュリティ/脆弱性対策に欠かせないスタックとヒープの基礎
スタックとヒープは組込みシステムの基本となる要素で、セキュリティ/脆弱性対策に直結し、適切に設定することがシステムの安定性と信頼性のために欠かせません。また誤った使い方はシステムの不具合につながるので注意が必要です。この記事では、スタックおよびヒープの基礎と設計方法をご紹介します。
スタックとヒープは、プログラマが設計し、静的に確保する必要があります。適切なスタックサイズを計算することは小規模な組込みシステムを除いて非常に難しいです。加えて、スタックサイズを小さく見積もると、検出しにくい深刻なエラーを招くことがあります。一方で、スタックサイズを過大に見積もると、メモリの無駄使いになります。スタックの必要量の見積もりは、実行時におけるスタックの最大の深さを把握することで、単純化できます。ヒープはひっそりとオーバーフローしますが、組込みシステムがこのような極端なメモリ不足から回復できることは稀で、実際には安心できません。
スタックとヒープの概念
記事の対象範囲
この記事では信頼性のあるスタックとヒープの設計と、必要なサイズを安全に最小化する方法をご説明します。
デスクトップシステムと組込みシステムにおいて、スタックとヒープの設計で考慮すべき点は共通する部分もありますが、多くの点で異なります。例えば、利用可能なメモリサイズが異なります。Windowsで1MB、Linuxで8MBのスタックサイズがデフォルトで、それ以上に設定することも可能です。ヒープの上限は物理メモリおよび仮想メモリ(ページファイル)のサイズによって制限されます。組込みシステムでは、RAMサイズの制限が大きいので、スタックとヒープを最小化するニーズがあります。小規模な組込みシステムでは一般的に仮想メモリが存在しません。つまり、スタック・ヒープ・グローバルなデータ(例えば、変数、TCP/IPやUSBのバッファなど)の確保は静的で、ビルド時に行います。
以下では、小規模な組込みシステムで発生するスタックとヒープに関連する問題を取り上げます。
限界を超える
日常生活で限界を超えることは、時にやりがいになる反面、トラブルにもなりえます。プログラミングにおいて、確保したメモリの限界を超えることは間違いなくトラブルになります。運が良ければ、すぐにトラブルが発生したり、テストで見つけられるかもしれません。しかし、数千もの顧客に製品が届けられた後や、遠隔地にシステムが展開された後など、遅すぎるタイミングで顕在化することもありえます。
割り当てたメモリがオーバーフローすることは、グローバルなデータ・スタック・ヒープの3種類のストレージ全てで起こります。配列またはポインタの参照先への書き込みは、オブジェクトに割り当てたメモリの外にアクセスすることがあります。一部の配列のアクセスは、コンパイラまたはMISRA Cチェッカにより、静的解析できます。
int array[32];
array[35] = 0x1234;配列のインデックスが変数の場合、静的解析では全ての問題を検出することはできません。ポインタによる参照も静的解析が困難です。
int* p = malloc(32 * sizeof(int));
p += 35;
*p = 0x1234;オブジェクトのオーバーフローを実行時に検出する手法はデスクトップシステムで長い間利用されており、Purify・Insure++・Valgrindなどが挙げられます。これらのツールは、ソースコードに検出用のコードを追加すること(インストゥルメンテーション)で、実行時にメモリ参照の妥当性を確認します。この方法には、アプリケーションの実行速度の大幅な低下とコードサイズの増加という代償があるため、小規模な組込みシステムおいては使いにくいです。
スタックの概要
スタックは主に以下を保存するメモリ領域です。
- ローカル変数
- 関数の戻り番地
- 関数の実引数
-
テンポラリ変数(計算の途中結果の保存などのためコンパイラが生成)
-
割り込みのコンテキスト
スタック上の変数の生存区間は関数の生存区間で決まります。関数の終了と同時に、使用されていたスタックは解放され、次に実行する関数で使用可能になります。
スタックはプログラマによって静的に確保する必要があります。プログラム実行時、スタックは(多くのアーキテクチャで)下方のアドレスに伸長します。確保したスタックが十分でない場合、静的に確保した領域を超えるアドレスに書き込みを行うことで、オーバーフローとなります。この時、書き込まれる領域は大抵グローバル変数や静的変数が保存されています。このためスタックサイズを小さく見積もることは深刻な実行時エラーを招きます。変数の上書き・ワイルドポインタ(不正なアドレスを参照するポインタ)・戻り番地の破壊、といったエラーを引き起こし、また全てのエラーを検出することは難しいです。一方で、スタックサイズを過大に見積もることはメモリの無駄につながります。
こうした背景から、信頼性高く必要なスタックサイズを計算する方法・スタックに関連する問題の検出について、後述します。
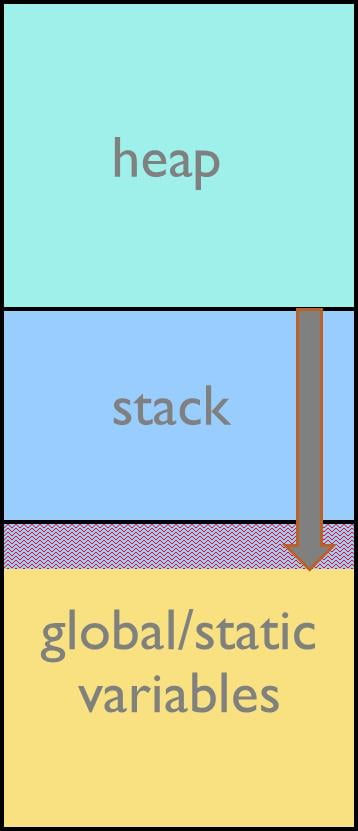
図1 : スタックオーバーフローが発生した状況
ヒープの概要
ヒープはシステムの動的メモリが置かれる領域です。小規模な組込みシステムおいて、動的メモリおよびヒープは任意で検討されるものです。動的メモリはプログラムの異なる箇所からメモリの共有を実現します。あるモジュールが確保していたメモリを使用しなくなった時点で、メモリアロケータに返却し、他のモジュールで再利用可能にします。
ヒープに配置されるデータの具体例は以下です。
-
一時的なオブジェクト
-
C++でnew/deleteするオブジェクト
-
C++のSTLコンテナオブジェクト
-
C++の例外(exception)
大規模システムではヒープに必要なサイズを計算することは困難か不可能です。なぜならアプリケーションの動的な振る舞いに依存するからです。さらに組込みの世界ではヒープの利用状況を計測するツールのサポートが少ないです。それでもいくつかの計算方法を後述します。
ヒープの整合性を維持することは重要です。割り当てた領域には、通常、メモリアロケータにとって重要なメモリ管理用のデータ(ハウスキーピングデータ)が存在します。割り当てたデータ領域を不正に使用すると、他のデータ領域が破損するだけでなく、メモリアロケータ全体が破損し、アプリケーションがクラッシュする可能性があります。
もう一つ考慮すべきは、ヒープの実行時の性能が事前に決定できない点です。メモリアロケーションにかかる時間は、以前の使用状況と要求する領域のサイズなどに依存します。
ヒープはこの記事の中心的な話題ですが、一般的なガイドラインとしては小規模な組込みシステムではヒープの使用を極力控えることとなります。
信頼性のあるスタックの設計
なぜスタックの必要量の計算が難しいのか?
スタック使用量の最大値を見積もるのが難しい理由はたくさんあります。多くのアプリケーションは複雑でイベントドリブン、数百の関数と割り込みで構成します。いつでも発生する可能性のある割り込み関数が存在し、かつ多重割り込みを許可する場合、正確な状況を把握することは一層難しくなります。さらに、多数の異なる関数を呼び出す可能性がある関数ポインタを使用した間接呼び出しもあるかもしれません。再帰呼び出しやアセンブリコードで記述したルーチンもスタック使用量の最大値を計算する上で問題になります。
多くのマイクロコントローラは複数のスタックを実装し、例えば、システム用のスタックとユーザ(アプリケーション)用のスタックです。μC/OS・ThreadXなど組込みRTOSを使用する場合、各タスクは個別にスタック領域を持ちます。ランタイム関数とサードパーティーのソフトウェアはソースコードが非開示のことがあり、その場合も計算を難しくします。ソースコードとアプリケーションのスケジューリングに対する変更も、スタックの使用量に大きな影響があるので、忘れてはなりません。また異なるコンパイラ・異なる最適化レベルは出力コードの差となり、スタックの使用量に違いが生まれます。以上を考慮して、スタックの最大使用量を継続的に記録しておくことが重要です。
スタックサイズの設定
アプリケーションを設計する時、必要なスタックサイズは考慮すべき要素で、スタックの総量を決定する方法が必要となります。たとえスタックに残りのRAMを全て割り当てるとしても、それで十分かはわかりません。1つの有効な手段としては、最悪の状況下(コールグラフが非常に深いケース)でのスタックの振る舞いをテストすることです。これらのテストによって、どれだけのスタックが必要か判明します。基本的には2種類の方法があり、1つは現在のスタック使用量を出力する、もう1つはテスト終了後にスタックの使用量に関するトレースを確認する、のいずれかになります。しかし、すでに述べた通り、ほとんどのシステムでは最悪の状況を意図して引き起こすのが困難です。多数の割り込みを含むイベントドリブンなシステムをテストする基本的な問題はいくつかの実行パスをテストすることができない可能性が高いことです。
別のアプローチはスタックサイズの最大値を理論的に計算することです。複雑なシステムに対して手計算することは不可能なので、システム全体を解析できるツールを利用します。ツールはバイナリイメージまたはソースコードのいずれかに対して動作する必要があります。バイナリイメージ向けのツールは、機械語レベルで動作し、ソースコード上のプログラムカウンタの動きを把握し、最悪ケースの実行パスを見つけます。ソースコードの静的解析ツールは全てのコンパイル対象を読み込みます。どちらの場合も、ツールは関数呼び出しと間接関数呼び出しを把握し、全てのコールグラフに渡り、保守的にスタック使用量の見積もりを行います。静的解析ツールはスタック上のコンパイラ用の領域(アライメントやテンポラリ変数)についても把握する必要があります。
この種のツールを自作するのは難しいですが、スタックの静的解析ツールまたはソリューションベンダ、例えばExpress Logic社のThreadX RTOSなど、商用の解決策があります。スタックが必要とする最大値を計算するための情報を持つその他のツールとしては、コンパイラとリンカがあります。例えばIARのEmbedded Workbench for ARMで利用できます。ここから実際にスタックサイズの見積もり方法を見ていきましょう。
スタックサイズの設定方法
スタックの深さを計算する一つの方法は現在のスタックポインタのアドレスを使用することです。これはローカル変数または引数のアドレスを取得することで可能です。main関数の入り口と大半のスタックを使用していると考える関数の入り口でこれを行うことで、アプリケーションが必要とするスタックサイズが概算できます。以下の例はスタックが上位のアドレスから下位に伸長すると仮定します。
char *highStack, *lowStack;
int main(int argc, char *argv[])
{
highStack = (char *)&argc;
// ...
printf("Current stack usage: %d\n", highStack - lowStack);
}void deepest_stack_path_function(void)
{
int a;
lowStack = (char *)&a;
// ...
}この方法は小規模で非決定的性(OSや割り込みなどの要素)を含まないシステムでは良好な結果が得られますが、多くのシステムでは最も深いスタックの使用をする関数の決定と最悪ケースを発生させるのが困難です。
かつ、上記の手法で得られた結果は割り込みを考慮していないことに注意が必要です。
他の方法としては、高い頻度で発生するタイマー割り込みのスタックポインタを定期的にサンプリングすることがあります。この時、タイマー割り込みの周波数はアプリケーションのリアルタイム性を損なわない範囲で最も高く設定する必要があります。通常、周波数は10-250kHzの範囲を想定します。この方法の利点は最も深いスタックを利用する関数を手作業で見つける手間がないことです。さらにタイマー割り込みが他の割り込み関数を許可するなら、割り込み関数の中におけるスタック使用量もわかる可能性があります。ただし、割り込み関数は多くの場合実行時間が短いのでサンプリング間隔によっては見逃すかもしれないので注意が必要です。
void sampling_timer_interrupt_handler(void)
{
char* currentStack;
int a;
currentStack = (char *)&a;
if (currentStack < lowStack) lowStack = currentStack;
}スタックガード領域
スタックガード領域はスタックの直下に確保するメモリ領域で、オーバーフローが起きた際にトレース情報を残します。この方法はデスクトップシステムでは常に実装され、OSはスタックオーバーフローによるメモリ保護エラーの検出をします。MMUを使用しない小規模な組込みシステムでも、ガード領域は有用です。ガード領域が有効であるために、ガード領域への書き込みを補足できるだけの十分なサイズが必要です。
ガード領域の一貫性チェックは、ガード領域に設定したパタンが無傷であることを定期的に確認して実現します。
MCUがメモリ保護ユニットを持つ場合、より良い方法が実装可能です。その場合、メモリ保護ユニットがガード領域への書き込みを検出可能です。ガード領域へのアクセスにより、例外を発生させ、例外ハンドラが解析のためのトレース情報を記録することが可能です。
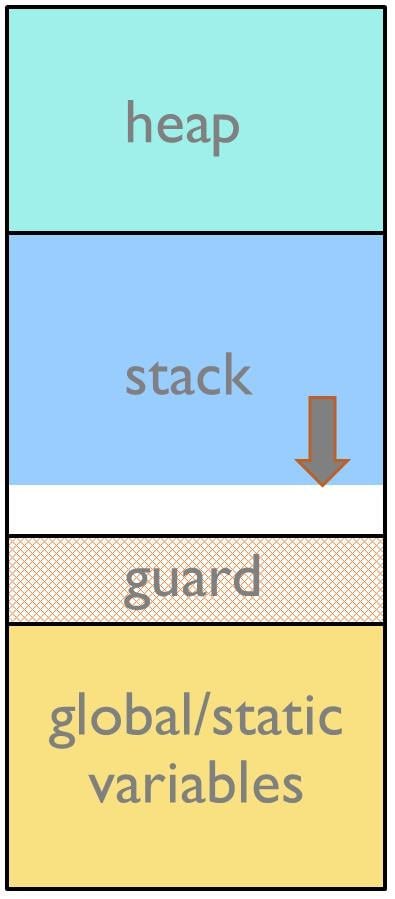
図2 : ガード領域を持つスタック
スタック領域を専用パタンで初期化
スタックオーバーフローの検出方法の一つに、スタック領域に割り当てたメモリ全体を専用の値によって初期化する方法があります。例えば、アプリケーションの実行開始前に0xCDなどで初期化します。実行が停止した際に、スタックの末尾から上方に0xCDが見つからない位置まで検索し、スタックがどこまで伸長したか推定します。0xCDが見つからなければ、スタックがオーバーフローしたことになります。
これはスタックの使用量をトレースする信頼性の高い方法ですが、スタックオーバーフローが確実に検出できる保証はありません。例えば、スタックが不正に領域外まで伸長し、そして領域外のメモリまで書き換えたとしても、スタック領域の境界付近のバイトを書き換えないケースもありえます。同様にアプリケーションの予期しない動作でスタック領域を書き換えてしまうこともあるかもしれません。
スタック使用量をモニタするこの方法はデバッガで広く使用われます。例えば図3が示すように、デバッガはスタック使用量をグラフィカルに表示できます。またデバッガは発生時点ではスタックオーバーフローを検出しません、発生後の兆候を検出するのみです。
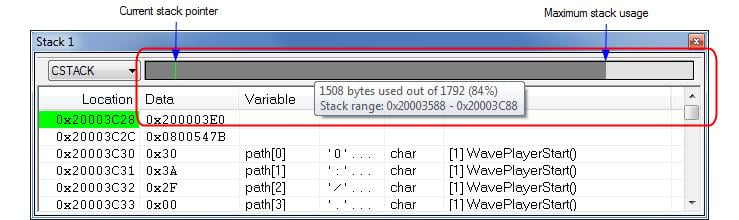
図3: Stack window in IAR Embedded Workbench
リンカによるスタックの最大使用量の見積もり
コンパイラやリンカがどのようにスタックの最大使用量を見積もるか、その詳細を見てみましょう。ここではIARのコンパイラとリンカを一例として示します。コンパイラが必須情報を出力し、リンカは各コールグラフのルート(例えばアプリケーションの開始のように他の関数から呼び出されない関数)からスタックの最大使用量を計算します。この方法は各関数の正確なスタック使用量が明らかな場合に正確です。
一般に、コンパイラが各関数のスタック使用量を生成しますが、ユーザがコンパイラにスタックに関する情報を提供しなければならない場合もあります。例えば、関数ポインタを使用した間接関数呼び出しが存在する場合、ユーザは呼び出す可能性のある関数のリストを提供する必要があります。これはpragma記述、またはリンク時にスタック使用量解析制御ファイルを利用することで実現できます。
void
foo(int i)
{
#pragma calls = fun1, fun2, fun3
func_arr[i]();
}スタック使用量解析制御ファイルを使用する場合、モジュールの中でスタック使用量の情報を持たない関数のスタック使用量の情報をリンカに提供できます。リンカは必要な情報が不足する場合に警告を出します。例えば、以下のような状況です。
-
スタック使用量の情報がない関数が一つ以上存在する。
-
アプリケーション中に間接関数呼び出しが存在し、間接関数呼び出しされる可能性がある関数のリストが提供されていない。
-
既知の間接関数呼び出しはないが、コールグラフのルートでなく、かつ呼び出しがない関数が存在する。
-
アプリケーションが再帰呼び出しを含む。
-
コールグラフのルートとして宣言された関数の呼び出しが複数存在する。
スタック使用量解析が有効な場合、スタック使用量の情報がマップファイルに追加されます。また各コールグラフルートの最大のスタック使用量も含まれます。

システム全体の最大のスタック使用量の合計は各コールグラフルートの結果を足すことで計算できます。上記の例では、500+24+24+12+92+8+1144+8+24+32+152 = 2020 bytesとなります。
スタック使用量解析は最悪ケースを示すことに注意が必要です。アプリケーションは、設計にせよ偶然にせよ、実際には最悪ケースが起こらないこともあります。
信頼性のあるヒープの設計
何が問題となるか?
ヒープの使用量を過少に見積もることはmalloc関数の中でメモリ不足のエラーを引き起こす可能性につながります。エラーはmalloc関数の戻り値をチェックすることで容易に検出できますが、それでは遅いでしょう。なぜなら、アプリケーションの再起動など、ほとんどのシステムではヒープの不足を回復する方法が受け入れられるものではないからです。一方で、ヒープの動的な性質から、使用量を大きめに見積もることが必須ですが、あまりに大きな見積もりはメモリの無駄遣いとなります。
その他にヒープの使用で起こる失敗は以下の2つです。
-
ヒープ領域の誤った上書き(変数・ポインタ)
-
ヒープの内部構造の破壊
以降の説明をする前に、動的なメモリに関するAPIをおさらいしましょう。
void* malloc(size_t size);-
引数は確保するメモリサイズ(byte)
-
戻り値は確保したメモリの先頭を指すポインタ
-
確保したメモリをクリアしない
-
利用可能なヒープがない場合、NULLを返す
free (void* p);-
ポインタpが指すメモリを開放する
-
引数はmalloc関数, calloc関数, realloc関数の戻り値で取得したポインタ
-
2回以上、同じポインタを使用してfree関数を呼び出してはいけない
void* calloc(size_t nelem, size_t elsize);-
malloc関数に類似した関数
-
確保したメモリ領域をクリアする
void* realloc(void* p, size_t size);-
malloc関数に類似した関数
-
確保されたブロックを伸長・縮小する
-
実行後はpが指していたアドレスが変わる可能性がある
C++-
new演算子はmalloc関数と類似した演算子
- new[]
-
delete演算子はfree関数と類似した演算子
- delete[]
たくさんの動的なメモリアロケーションの実装が存在します。もっとも広く使用されているものはDlmalloc(Doug Lea’s Memory Allocator)です。DlmallocはLinuxと多数の組込みシステムの開発ツールで利用されてます。Dlmallocはフリーで利用可能です。
ヒープの内部構造にはアプリケーションによって割り当てられたデータが散在します。アプリケーションが割り当てたデータの外を書き換えるとヒープは簡単に破壊されます。
図5は単純化した図として、割り当てたデータ領域の周辺にどのようなデータ構造が存在するかを示します。図5で明らかなように、アプリケーションによって割り当てたデータ領域の外を書き換えることでヒープの破壊が破壊されます。
ヒープが必要とするメモリの総量を計算することは些細なことではありません。設計者の多くは試行錯誤をします。典型的な方法としては、アプリケーションが動く最小のヒープサイズを見つけ、それに50%加算するという方法です。
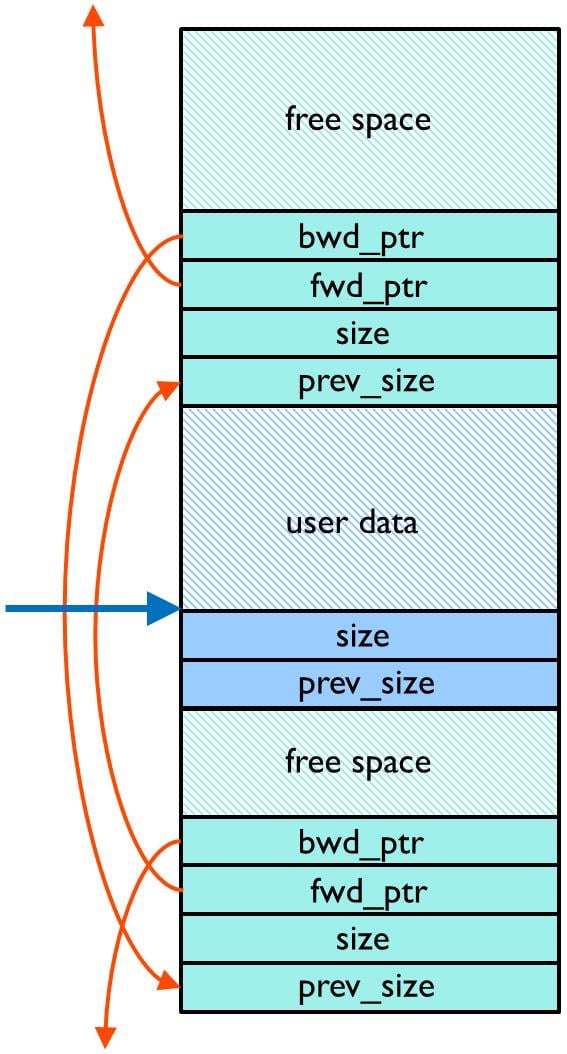
図5:ヒープの内部構造
ヒープに関するエラーの予防
プログラマとソースコードのレビュワが知っておくべきいくつか一般的なエラーがあります。これらは製品立ち上げにおいてヒープのエラーが混入するリスクの減少につながります。
•初期化に関するミス
「未初期化のグローバルなデータは常にゼロに初期化される。」、このよく知られた事実がヒープも同様と誤解させます。前述のとおり、malloc関数, realloc関数, new演算子は割り当てた領域の初期化をしません。callocだけがmallocの特別な派生として割り当てた領域をゼロで初期化します。C++のnew演算子では、適切なコンストラクタが呼び出されるので、全ての要素を初期化するようにしましょう。
•スカラ型と配列型の区別に関するミス
C++はスカラ型と配列型で異なる演算子をサポートします。newとdeleteはスカラ型用、new[]とdelete[]は配列型用です。
•解放済みのメモリへの書き込み
これはメモリアロケータのデータ構造の破壊、または後に割り当てたデータへの書き込みよって上書きされることになります。いずれの場合も検出が難しいエラーです。
•戻り値のチェックのミス
malloc関数, realloc関数, calloc関数はメモリ不足を示すためにNULLポインタを戻します。デスクトップシステムはメモリフォールトを発生させるので、メモリ不足の状態を開発中に容易に検出できます。組込みシステムはアドレス0にフラッシュメモリがあり、より微妙なエラーで実行を続けてしまうことがあります。もしMCUがメモリ保護ユニットを持つなら、フラッシュメモリなど実行専用の領域への書き込みについて、メモリ保護違反を発生するよう設定することが可能です。
•同じメモリ領域を複数回freeする
これはメモリアロケータのデータ構造を破壊し、検出が非常に困難です。
•割り当てたデータの外への書き込み
これはメモリアロケータのデータ構造を破壊につながり、検出が非常に困難です
最後の3つのエラーは、malloc関数,free関数および関連関数の周辺にラッパーを追加することで、容易に検出が可能です。ラッパーは、ヒープ領域の一貫性チェックのための追加情報用に、数バイトの追加のメモリを使用します。図6で示すラッパーのデータレイアウトの例では、上部にあるマジックナンバーがヒープの破壊を検出するために使用され、メモリが解放されたときにチェックをされます。
データの下部にあるサイズのフィールドはマジックナンバーを見つけるためfree関数のラッパーに使用されます。ラッパーの例はメモリを割り当てるごとに8バイトのオーバヘッドがあり、この大きさは多くのアプリケーションで問題ないと想定します。この例ではC++のnewとdelete演算子をどのようにオーバライドすれば良いかも示します。この実装は、割り当てたメモリが全てある時点で解放された場合のみ、このような全てのエラーを検出できます。
ただし、適用できないアプリケーションもあります。その場合、ラッパーは全てのメモリアロケーションのリストを維持し、定期的にリストの妥当性をチェックする必要があります。組込みシステムの多くは動的メモリの利用は限定的で、メモリアロケーションのリストはそれほど大きくないので、この実装のオーバヘッドは想像するより大きくないでしょう。
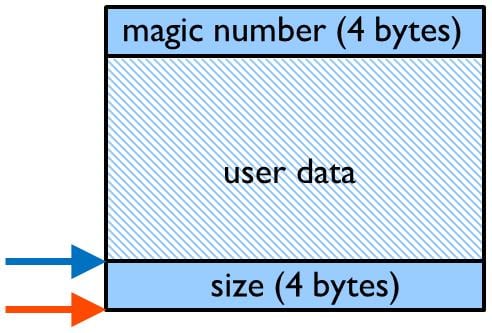
図6:ラッパーのデータレイアウト
#include <stdint.h>
#include <stdlib.h>
#define MAGIC_NUMBER 0xefdcba98
uint32_t myMallocMaxMem;
void* MyMalloc(size_t bytes)
{
uint8_t *p, *p_end;
static uint8_t* mLow = (uint8_t*)0xffffffff; /* lowest address
returned by
malloc() */
static uint8_t* mHigh; /* highest address + data returned by
malloc() */
bytes = (bytes + 3) & ~3; /* ensure alignment for magic number */
p = (uint8_t*)malloc(bytes + 8); /* add 2x32-bit for size and magic
number */
if (p == NULL)
{
abort(); /* out of memory */
}
*((uint32_t*)p) = bytes; /* remember size */
*((uint32_t*)(p + 4 + bytes)) = MAGIC_NUMBER; /* write magic number
after
user allocation */
/* crude method of estimating maximum used size since application
start */
if (p < mLow) mLow = p;
p_end = p + bytes + 8;
if (p_end > mHigh) mHigh = p_end;
myMallocMaxMem = mHigh - mLow;
return p + 4; /* allocated area starts after size */
}
void MyFree(void* vp)
{
uint8_t* p = (uint8_t*)vp - 4;
int bytes = *((uint32_t*)p);
/* check that magic number is not corrupted */
if (*((uint32_t*)(p + 4 + bytes)) != MAGIC_NUMBER)
{
abort(); /* error: data overflow or freeing already freed memory */
}
*((uint32_t*)(p + 4 + bytes)) = 0; /* remove magic number to be
able to
detect freeing already freed memory */
free(p);
}
#ifdef __cplusplus
// global override of operator new, delete, new[] and delete[]
void* operator new (size_t bytes) { return MyMalloc(bytes); }
void operator delete (void *p) { MyFree(p); }
#endif
ヒープサイズの設定方法
アプリケーションに必要なヒープサイズの最小値をどのように見つけることが可能でしょうか?ヒープの振る舞いは動的で断片的な状況になりますので、解決策は簡単ではありません。推奨できるアプローチとして、動的なメモリを可能な限り使うよう設計したテストケースのもと、アプリケーションを実行することが挙げられます。また少ないメモリの使用量から変化させていき、メモリの断片化といった影響を、繰り返し見ていくことが重要です。テストケースが完了したら、ヒープの最大使用量と実際のヒープサイズを比較しましょう。アプリケーションの性質によって、マージンとしては25-100%を充てましょう。
sbrk関数をエミュレートし、デスクトップシステムを模倣するシステムでは、ヒープの使用量の最大値はmalloc_max_footprint関数で得られます。
sbrk関数をエミュレートしない組込みシステムでは、メモリアロケータに対してヒープ領域を一括して与えるのが一般的です。その場合、malloc_max_footprint関数は意味がありません。その関数は単純にヒープサイズを返すだけです。解決策として、mallinfo関数をmalloc関数の呼び出し毎に呼び出すこと、があります。例えば、前述のラッパー関数で、割り当てた領域の全体を観察することができます(mallinfo->uordblks)。Mallinfo関数は計算量が多く、性能に影響します。より速い方法としてはヒープに割り当てた領域の最長の長さを記録することです。これは単純に実装でき、ラッパーの例に記載しています。ヒープ領域のアドレスの最大値は変数myMallocMaxMemに記録されます。この方法はヒープが連続したメモリ領域である場合に有効です。
まとめ
組込みシステムの安全性/セキュリティ/脆弱性の基本となるスタックとヒープの概要をご紹介しました。適切なスタックとヒープの設定は組込みシステムの信頼性を高くするために重要です。たとえスタックとヒープの使用量を計算することが複雑で難しくても、便利なツールや解決策があります。また、開発フェーズにおいて正確な計算をするために費やしたコストは、運用が始まったシステムでスタックとヒープの破壊により起こる問題を発見しないで済むだけでも、見合った価値があります。
参考文献
- Nigel Jones, blog posts at embeddedgurus.com, 2007 and 2009
- John Regehr ,“Say no to stack overflow”, EE Times Design, 2004
- Carnegie Mellon University , “Secure Coding in C and C++, Module 4, Dynamic Memory Management”, 2010
ウェビナー(オンラインセミナー)
オンデマンドウェビナー