掌控堆栈,确保系统稳定
堆(Heap)和栈(Stack)在嵌入式系统中是非常基础的概念。正确设置堆和栈的大小对于系统的稳定性和可靠性非常重要。设置不正确时,系统可能会以某种非常奇怪的方式崩溃而造成灾难性的后果。 堆和栈的内存必须被程序员静态分配。除了最小的嵌入式系统外,计算栈使用都是非常困难的,低估栈的使用可能会导致很难发现的严重运行时错误。另一方面,给栈分配过多的空间也意味着对内存资源的浪费。对于大多数嵌入式项目来说,最坏情况下,栈的最大深度是一个非常有用的信息,因为它大大简化了对应用程序所需栈大小的估计。虽然堆内存不会突然地溢出,但这也并不是什么好事,因为很少有嵌入式应用能够在这种极端的内存缺失情况下恢复。
1. 关于栈和堆的简介
范围
重点介绍如何设计可靠的栈和堆,以及如何以安全的方式最小化堆和栈。
尽管桌面系统和嵌入式系统有一些共同的设计错误和注意事项,但在许多方面却完全不同。一个不同的例子就是可用的内存大小。Windows 和 Linux 中默认设置 1和8 Mbytes 作为栈空间,并且可以再增加。而堆空间仅仅受限于可用物理内存和/或页文件大小。而在嵌入式系统中,内存资源非常有限,尤其是RAM 空间。因此,在这样受限的环境下,尽可能减少堆和栈的大小是非常必要的。一般来说,小型嵌入式系统中都不使用虚拟内存机制,堆和栈,全局数据(比如变量、TCP/IP、USB 缓冲区等)的分配是静态的,并且在程序构建时就已经被分配了。
下面我们会解决一些在小型嵌入式系统中出现的特殊问题,但我们并不会讨论如何保护堆栈免受攻击,这在桌面和移动设备中是一个非常热门的话题,如果说现在嵌入式系统还没有这个问题的话,在未来也极有可能会出现。
突破限制
在日常生活中不断地突破限制是值得的,尽管有时也会让您处于困境。而在编程期间分配数据时突破限制则一定会让您处于麻烦之中。幸运的是,这种情况可能会很直接的出现,比如出现在系统测试期间,但也有可能出现的很晚,以至于产品已经分发到很多用户手中或者部署在远程环境中。
溢出分配的数据可能发生在如下三个存储区域:全局变量内存区,栈内存区,堆内存区。写数组或者指针引用也可能会访问到分配给对象内存之外的区域。一些数组访问可以被静态分析验证,例如使用编译器和 MISRA C 检查器,具体如下:
int array[32];
array[35] = 0x1234;但当数组索引是一个变量表达式时,静态分析可能无法找出所有的问题。另外,指针的引用也很难通过静态分析来追踪,例如:
int* p = malloc(32 * sizeof(int));
p += 35;
*p = 0x1234;对于桌面系统,长久以来都在用运行时方法来捕捉对象溢出错误,例如 Purify、Insure++ 和 Valgrind。这些工具通过在应用程序运行时插入验证内存引用的代码来实现。这是以大幅降低应用程序执行速度和增加代码大小为代价的,因此这种方法并不太适于小型嵌入式系统。
栈
栈是一块用于存储程序数据的内存区域,例如:
- 局部变量
- 返回地址
- 函数参数
- 编译器临时变量
- 中断上下文
栈中变量的生命周期受限于函数的执行时间。函数返回后,其所使用的栈内存将被释放,供后续函数调用使用。
栈内存必须由程序员静态分配。栈通常在内存中向下增长,如果为栈分配的内存区域不够大,执行的代码就会写到栈下面分配的区域,出现溢出的情况。写入的区域通常是存储全局变量和静态变量的区域。因此,低估栈的使用会导致严重的运行时错误,如覆盖变量、野指针和返回地址错误,所有这些错误都是很难发现的。另一方面,给栈分配过多的空间也意味着对内存资源的浪费。
我们将重点介绍一些可以用来可靠地计算所需栈大小和检测栈相关问题的方法。
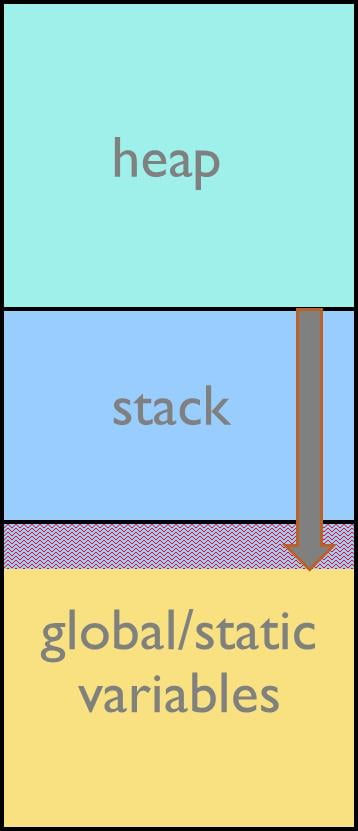
图1: 栈溢出情况
2. 可靠的栈设计
为什么计算栈会如此困难?
有许多因素使得计算最大栈使用变得困难。比如许多应用程序不仅复杂,而且由事件驱动,包含数百个函数和许多中断。其中一些中断函数可以随时被触发,如果允许它们嵌套,情况就变得更难掌握了,这意味着程序的执行流程变得难以追踪。另外,可能会有使用函数指针的间接调用,其调用的目标可能是许多不同的函数。递归和未注释的汇编例程也会给希望计算最大栈使用的人带来问题。
许多微控制器实现了多个栈,例如,一个系统栈和一个用户栈。如果使用像 μC/OS、ThreadX 等嵌入式 RTOS,多重栈是必须的,因为每个任务都拥有自己的栈区域。运行时库和第三方软件同样会使计算变得复杂,因为库和 RTOS 的源代码通常是不开放的。另外请注意,修改代码或是应用程序的调度顺序也可能会极大影响栈的使用量。不同的编译器和优化等级会产生不同的代码,这同样影响栈的使用量。总之,持续追踪栈的最大使用是非常有必要的。
如何设置栈的大小
设计应用程序时,栈的大小是一个需要考虑的因素,因此您需要一种方法来确定所需的栈大小。就算您将 RAM 全部的剩余空间都分配给栈使用,也未必足够。一个可行的办法是测试系统在最坏情况下所需的栈大小。在这样的测试中,您需要一种方法检测到底使用了多少栈空间。简单来说有两种途径,通过打印输出当前的栈使用,或是在测试结束后追踪内存中的栈使用。但正如前文所述,在许多复杂的系统里,这种最坏情况是很难被捕获的。根本原因在于当测试某些带有中断的事件驱动系统时,部分程序执行路径可能根本没有被测试到。
另一种方法是从理论上计算最大栈的需求。显然,手动计算一个完整的系统是不可能的。这种计算必须用到一个可以分析整个系统的工具,并且,这个工具可以分析二进制文件映像或者源代码。如果是分析二进制文件,则需要在机器指令级别找出代码中所有程序指针的变化,从而找到最坏情况下的执行路径。如果是静态分析源代码,则需要读取所有包含的编译单元。对于这两种情况,分析工具都必须通过编译单元中的指针确定直接函数调用和间接函数调用,并通过所有调用图计算出保守的系统栈使用概要。此外,源代码分析工具需要知道编译器对栈的一些设置,例如对齐方式和编译器临时变量。
光靠自己独立编写一个这样的工具无疑是非常困难的,因此也有一些商业替代方案。例如独立的静态栈计算工具,或是由解决方案提供商提供的工具,比如 Express Logic的 ThreadX RTOS 的栈计算工具。此外,编译器和链接器也可以被用于计算栈最大需求量信息。这个功能可以在诸如 IAR Embedded Workbench 之类的工具上获得。现在,我们来看一些可以被用于预估栈使用的方法。
不同的设置栈大小的方法
一种计算栈深度的方法是检测当前栈指针的地址。这可以通过获取函数参数或是局部变量的地址来实现。如果在main函数起始处和您认为的可能占用最多栈空间的函数中获取到栈指针的地址,您就可以计算出栈的最大需求量。这里有一个例子,我们假设栈从高地址向低地址增长:
char *highStack, *lowStack;
int main(int argc, char *argv[])
{
highStack = (char *)&argc;
// ...
printf("Current stack usage: %d\n", highStack - lowStack);
}void deepest_stack_path_function(void)
{
int a;
lowStack = (char *)&a;
// ...
}对于小型和确定性的系统,这种方法可以得到很好的结果,但是在很多系统里,您很难确定栈调用最深的嵌套函数和和触发的最坏情况。
请注意,这种方法获取到的栈使用并不将中断函数所需的栈使用考虑在内。
这个方法的一个变种可以解决这个问题,即通过一个高频的定时器中断定期对栈指针进行采样。应尽可能将这个中断频率设置到最高而不影响应用程序的实时性能。通常设置为 10~250 Khz 之间。这种方法的好处在于您不需要手动去寻找最大栈使用的函数。另外,当采样中断可以抢占别的中断时,这种方法也可以统计出中断函数所需的栈使用。然而,由于中断函数通常都会迅速执行完毕,因此可能会被周期采样中断所遗漏。
void sampling_timer_interrupt_handler(void)
{
char* currentStack;
int a;
currentStack = (char *)&a;
if (currentStack < lowStack) lowStack = currentStack;
}栈保护区
栈保护区就在栈分配的内存区下方,用来检测栈是否溢出。桌面系统通常都会实施这种方法,以便在栈发生溢出时,可以轻松设置操作系统以检测内存保护错误。对于不具备 MMU 的小型嵌入式系统,栈保护区也可以插入并发挥作用。为了使栈保护区生效,必须设置一个合理的大尺寸,用以捕捉写入保护区的操作。
可以通过软件周期性检测栈保护区的填充模式是否完整来对其进行一致性检测。
如果 MCU 配备了内存保护单元,可以实施一个更好的方法。在这种情况下,内存保护单元可以被设置为在数据写入到保护区时触发。这些写入访问将触发一个异常,由异常处理程序记录所发生的情况,以便未来分析。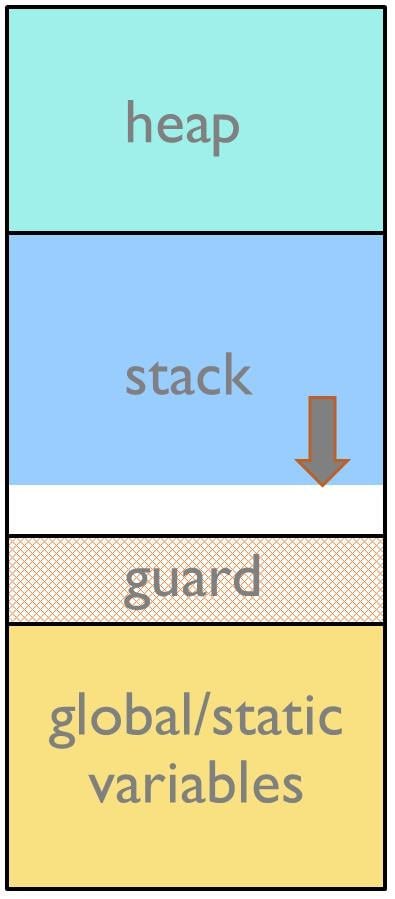
图2: 拥有保护区的栈
使用特定模式填充栈区
一个检测栈溢出的技术是在应用程序开始执行前,用一个专门的填充值,例如 0xCD,填充分配给栈区域的全部内存。不论应用在什么位置停下,都可从栈的低地址向上查找,直到找到一个不等于 0xCD 的位置,通过这个位置就可以算出栈的使用量。如果根本找不到这个值,那说明栈发生了溢出。
尽管这是一个检测栈使用量的可靠方法,但这并不能保证一定能检测到栈溢出。例如,栈可能不正确的在其边界外增长,甚至改变了栈区域以外的内存,但是栈以内的数据没有被修改的情况。同样地,您的应用程序也有可能错误地修改了栈区域的内存,从而发生误判。
通常,可以使用调试器监测栈的使用。调试器可以展示一个如图 3 一样的界面来表示栈使用。但请注意,调试器通常并不能检测到栈溢出,它只能检测到溢出发生后的留下的踪迹。
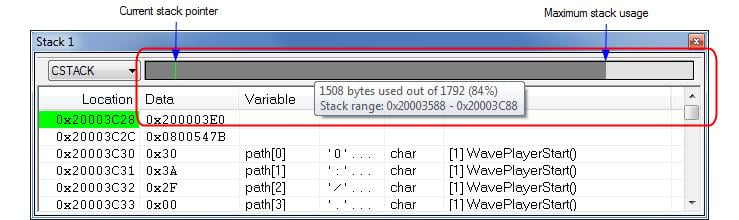
图3: IAR Embedded Workbench中的栈窗口
链接器计算的最大栈需求量
我们现在来看一看构建工具,例如编译器和链接器是如何计算栈的最大需求量的。我们将使用 IAR 编译器和链接器来进行说明。编译器可以产生重要的信息,而链接器在正确的情况下可以准确计算出每一个根函数(不被别的函数调用,例如主函数)所需的最大栈使用。只有在应用程序中每个函数的栈使用信息都准确时,最终的结果才是准确的。
通常来说,编译器可以为每一个 C 函数生成栈使用信息,但在一些特殊情况下,您必须提供与栈有关的信息给系统。例如,当应用程序中存在间接调用函数(使用函数指针)时,您必须为每个调用函数提供一个可能被调用的函数列表。您可以通过在源文件中添加预编译指令实现,也可以在链接时使用一个分离的栈使用控制文件实现。
void
foo(int i)
{
#pragma calls = fun1, fun2, fun3
func_arr[i]();
}如果使用了栈使用控制文件,您也可以为模块中没有栈使用信息的函数添加栈使用信息。如果某些重要信息被遗漏,链接器同样会产生警告,例如出现下面这些情况时:
- 至少有一个函数没有栈使用信息。
- 应用中至少有一个间接调用没有提供可能被调用的函数列表。
- 没有已知的间接调用,但至少有一个没有被调用的函数不是已知的根函数。
- 应用程序中出现递归(调用图中的循环)。
- 出现调用的函数被声明为根函数。
开启栈使用分析之后,栈使用说明将被添加进链接器的映射文件,上面列出了每一个根函数特定的调用链,这会导致栈的最大深度。

图4:链接器计算的最大栈使用
将每一个根函数的栈使用加在一起就是整个系统的栈最大使用。在上面这个分析中,栈所需的最大使用可能是 500+24+24+12+92+8+1144+8+24+32+152 = 2020 字节。
需要记住的是,这种方法产生的是最坏情况下的结果。不管是刻意执行或者巧合发生,应用实际上都不可能需要这么多栈。
3. 关于堆的简介
堆是系统的动态内存所在的地方。在一些小型嵌入式系统中,动态内存和堆在很多情况都是可选的。动态内存使得程序的不同部分之间可以共享内存。当一个模块不再需要其分配的内存时,它只需将其返回到内存分配器中,即可由其他模块重新使用。
存储在堆上的数据示例包括:
- 临时数据对象
- C++ new/delete
- C++ STL containers
- C++ exceptions
由于应用程序的动态行为,在较大的系统中计算堆空间是非常困难,甚至是不可能的。此外,在嵌入式世界中,没有足够的工具支持来测量堆的利用率,但本文还是将探讨一些方法。
保持堆的完整性是很重要的。分配的数据空间通常与关键的内存分配器内部数据穿插在一起。错误地使用分配的数据空间,不仅会有破坏其他数据空间的风险,而且可能会破坏整个内存分配器,最终导致应用崩溃。下面,我们将探讨一些方法来检查堆的完整性。
另一个需要考虑的方面是,堆的实时性能不是确定性的。内存分配时间取决于诸如以前的使用和请求的数据空间大小等因素。这几乎不在熟悉循环驱动开发模式的嵌入式开发人员的愿望清单上。
尽管堆是本文的一个核心话题,但通用的准则就是在小型嵌入式系统中尽量减少堆的使用。
4. 可靠的堆设计
会出现什么错误?
低估堆的使用会导致 malloc() 中出现内存不足的错误。通过检查 malloc() 的返回状态可以很容易检测到它,但为时已晚。这是一种严重的情况,因为很多系统没办法从中恢复,只能重新启动应用。由于堆的动态性,高估堆的使用是很有必要的,但是分配太多则又导致内存资源的浪费。
在使用堆时,可能会出现另外两种错误:
- 覆盖堆数据(变量和指针)
- 堆内部结构损毁
在阅读下文之前,让我们复习一下动态内存 API:
void* malloc(size_t size);- 分配size大小的内存
- 返回一个指向所分配内存块的指针
- 内存块不清零
- 如果没有剩余的内存,则返回 NULL
free (void* p);- 释放 p 指向的内存空间
- 要求 p 在之前调用 malloc()、calloc() 或 realloc() 时已经被返回
- 必须避免对同一个 p 多次调用 free(p)
void* calloc(size_t nelem, size_t elsize);- 类似于 malloc()
- 清零内存块
void* realloc(void* p, size_t size);- 类似于 malloc()
- 增加/缩减一个先前分配的块
- 返回的块可能有一个新的地址
C++- new operator – 类似于malloc()
- new[]
- delete operator – 类似于 free()
- delete[]
有很多的方法可以实现动态内存分配。目前最常用的是 Dlmalloc(Doug Lea 的内存分配器)。Dlmalloc 被用于 Linux 和许多嵌入式系统的开发工具之中。Dlmalloc 可以免费获取并且是开源的。
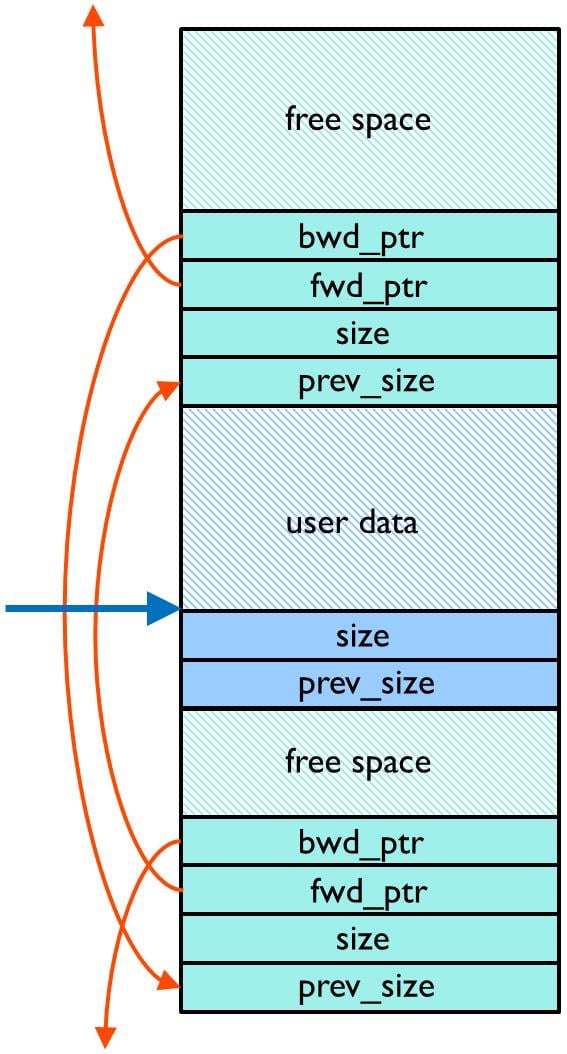
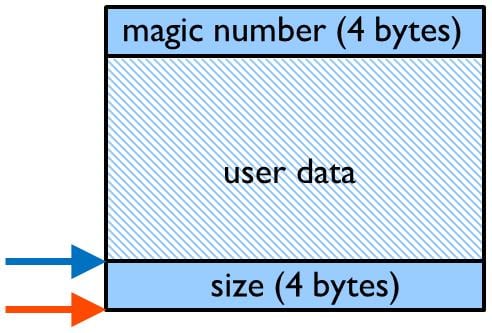
堆的内部结构和应用程序分配的数据穿插在一起。如果应用程序往分配的数据区外写数据,很有可能会破坏堆的内部结构。
下图是一个多种数据结构围绕分配的用户数据区交错分布的一个简化视图。从图中可以明显看出,若应用在超出分配的用户数据区外任何写的操作,都会严重破坏堆。
计算堆所需的内存量是一个重要的任务。大多数设计者会采用试错的方法,因为其他方法太过繁琐。典型的算法是:找到一个能使系统正常运行所需的最小堆,之后在这个基础上多分配 50% 内存。
预防堆错误
以下是一些程序员和代码审阅者都需要知道的常见错误,这可以尽量避免发布的产品中出现堆错误。
- 初始化错误
未初始化的全局数据始终都被初始化为 0。这个众所周知的事实会让我们很容易假定在堆也一样。然而,malloc(),realloc() 和 C++ new 都不对分配的数据进行初始化。只有一个 malloc() 的变种函数 calloc() 会对分配的数据进行清零操作。在 C++ 中使用 new,会调用对应的构造函数,因此请确保对每个元素执行了初始化操作。
- 错误地区分标量和数组
C++ 对标量和数组有不同的操作符,new 和 delete 用于标量,new[] 和 delete[] 用于数组。
- 向已被释放的内存写入数据
这要么会破坏内部内存分配器的数据结构,要么会在以后被写入合法分配的区域而覆盖。不论是哪一种情况,都很难被捕获。
- 未检查返回值
malloc()、realloc() 和 calloc() 在内存不足时都会返回 NULL 指针。出现这种情况时,桌面系统会产生一个内存空间不足的错误,因此在开发时可以很容易地检测到。嵌入式系统可能会从 0 地址开始编码,并且可能在出现更细微的错误时仍然存在。如果您的 MCU 具有内存保护单元,您可以将其设置为当应用程序试图向闪存和其他只执行区域写入数据时产生一个内存保护错误。
- 多次释放同一内存
这将破坏内部内存分配器的数据结构,并且很难被检测到。
- 写入的数据超出了分配的区域
这将破坏内部内存分配器的数据结构,并且很难被检测到。
后面的三种错误也可以容易检测到,前提是将标准 malloc()、free() 或相关函数做一个封装。封装意味着您需要申请一些额外的内存空间来存储用于一致性校验的信息。关于封装的结构图如图 6 所示。顶部的“magic number“用于检错,并且在释放数据空间时用于校验。在数据区域下方的大小字段,被 free() 封装用来查找“magic number“。这样的封装会对每一次分配的数据区增加 8 字节空间,这对于大部分的应用程序来说都是可以接受的。这个示例也展示了如何全局重载 C++ 的 new 和 delete 操作符。只有在所有分配的内存都在某个时间点被释放的情况下,这个例子才会捕捉到所有这样的错误。在一些应用程序中情况可能并非如此。在这种情况下,封装必须维护所有内存分配的列表,并且定期检查其是否正确。这种实现所带来的开销并不如其听上去那么多,因为大部分的嵌入式系统仅使用少量的动态内存,将分配列表保持在一个合理的限度内。
#include <stdint.h>
#include <stdlib.h>
#define MAGIC_NUMBER 0xefdcba98
uint32_t myMallocMaxMem;
void* MyMalloc(size_t bytes)
{
uint8_t *p, *p_end;
static uint8_t* mLow = (uint8_t*)0xffffffff; /* lowest address
returned by
malloc() */
static uint8_t* mHigh; /* highest address + data returned by
malloc() */
bytes = (bytes + 3) & ~3; /* ensure alignment for magic number */
p = (uint8_t*)malloc(bytes + 8); /* add 2x32-bit for size and magic
number */
if (p == NULL)
{
abort(); /* out of memory */
}
*((uint32_t*)p) = bytes; /* remember size */
*((uint32_t*)(p + 4 + bytes)) = MAGIC_NUMBER; /* write magic number
after
user allocation */
/* crude method of estimating maximum used size since application
start */
if (p < mLow) mLow = p;
p_end = p + bytes + 8;
if (p_end > mHigh) mHigh = p_end;
myMallocMaxMem = mHigh - mLow;
return p + 4; /* allocated area starts after size */
}
void MyFree(void* vp)
{
uint8_t* p = (uint8_t*)vp - 4;
int bytes = *((uint32_t*)p);
/* check that magic number is not corrupted */
if (*((uint32_t*)(p + 4 + bytes)) != MAGIC_NUMBER)
{
abort(); /* error: data overflow or freeing already freed memory */
}
*((uint32_t*)(p + 4 + bytes)) = 0; /* remove magic number to be
able to
detect freeing already freed memory */
free(p);
}
#ifdef __cplusplus
// global override of operator new, delete, new[] and delete[]
void* operator new (size_t bytes) { return MyMalloc(bytes); }
void operator delete (void *p) { MyFree(p); }
#endif
如何设置堆的大小
我们如何确定应用程序所需的堆的最小值?由于应用程序动态运行并且可能出现碎片,因此这个问题的答案是非常重要的。在这里我们推荐的方法是在应用程序动态分配内存尽可能多地占满堆内存的情况下去测试应用。从一个小内存反复测试可能出现的碎片带来的影响是非常有必要的。测试完成后,出现的堆的最大使用量即是实际的堆大小。依据具体的应用特点,应考虑留出 25%~100% 的余量。
对于通过仿真 sbrk() 来模拟桌面系统的系统,最大的堆使用量将由malloc_max_footprint() 给出。
嵌入式系统并不模拟 sbrk(),内存分配器通常将整个堆分配在一块内存上。因此 malloc_max_footprint() 函数是没用的,它仅仅返回整个堆的大小。一个解决方案就是在每次调用 malloc() 后,调用 mallinfo(),例如之前提到的封装的例子,然后观察分配空间的总大小(mallinfo->uordblks)。请注意,Mallinfo() 属于计算密集型函数,可能会对性能产生影响。一个更好的方法是记录分配区域之间的最大距离。这很容易完成,并且如封装示例中展示的那样,最大值记录在变量myMallocMaxMem 中。这种方法在堆是一块连续的内存区域时有用。
结论
设置合理的栈和堆区域对于一个安全可靠的嵌入式系统来说是非常重要的。虽然计算栈和堆所需的内存空间大小是非常复杂和困难的,但是我们有大量实用的工具和方法。为了在部署的系统中不出现栈和堆溢出情况,在开发阶段付出再多的时间和金钱都是值得的。
参考资料:
- Nigel Jones, blog posts at embeddedgurus.com, 2007 and 2009
- John Regehr ,“Say no to stack overflow”, EE Times Design, 2004
- Carnegie Mellon University , “Secure Coding in C and C++, Module 4, Dynamic Memory Management”, 2010