Back to the roots – tracing and debugging as a way to increase efficiency
Debugging embedded software is often a time-consuming activity, both in terms of chasing down a specific bug and as a general project activity. Further, as an activity, it is often an eclectic mix of desperation, perspiration and a fair bit of magical thinking.
In this article, I will cover techniques and tactics that might not completely eliminate all the hassles of debugging, but can at least minimize the magical part. If you are a relative newcomer to the embedded software world, you might pick up some useful nuggets of information. If you are a seasoned pro, you are probably aware of these topics, but you might then re-discover some techniques that you already know that you should practice.
Code quality as a base
We know for a fact that newly written software is seldom, if ever, completely bug-free. However, we also know that there are actions we can take up front to help us reduce the number of issues we have to deal with in our code, which is another way to say that we will have less debugging to do. An obvious place to start is to lay down some basic rules for code hygiene. Here’s a summary of some rules:
- Use a coding standard. MISRA and CERT C is a good place to start. Striving for MISRA compliance will help you avoid quite a few of the pitfalls inherent in C and C++, and CERT C will add a security perspective to the list of things to avoid. The first corollary is to pay close attention to your compiler warnings. The second corollary to this advice is to use an automated static checker to check your compliance.
- Use your own, or someone else’s, hardware abstraction layer. Avoid inlining code that directly manipulates hardware in your code. For example, if you need to start a timer, do so by calling a HAL function to set up and start the timer instead of directly manipulating the timer registers. Following this advice will have numerous advantages, of which one is that you will almost completely avoid copy/paste errors and typo mistakes when dealing with e.g. several different timer invocations in different places of the code base. Moreover, a compiler can often do a better job at optimizing, and might even inline the code, so you actually gain in both performance and code size. A corollary to this advice is to keep the individual HAL functions as small as possible – avoid creating "Swiss Army Knives" (large functions with many responsibilities). Not only are small, single-purpose functions easier to understand and maintain, they are also often easier for a compiler to optimize really well, which may seem a bit counterintuitive.
- Give some extra thought to how you use memory. For example, do you really need dynamic memory management? Is the stack really a good place to store complex data structures? Standards for functional safety and high-integrity software often advise strongly against dynamic memory management, and storing complex or large data structures on the stack, and these are for good reasons.
- If your toolchain supports worst-case stack depth analysis, the investment to read up on and use that functionality will pay off quickly.
To printf or not to printf should not be the question
One of first things to realize (or remember) is that if you are developing and debugging embedded software, you are very likely to do so in an environment where executing code on the target is done through a debugger. For example, if you are working in an IDE, the easiest way to execute your program is by firing up the debugger. This is sort of obvious, but it also means that you have all the powers of the debugger at your fingertips – maybe without realizing it.
To get down to the nitty gritty, we will examine the power of breakpoints. But first, let’s throw some shade at the venerable printf as a debugging tool. The most important reason to not use printf is that adding printf-statements in your code can have dramatic effects on how your code is compiled. Not only is the printf a function call, but the arguments to the call will have to be accounted for. This in turn means that stack and register usage will look completely different and a lot of compiler optimizations will not be performed, especially if the statement is located in a tight loop. This can have unpredictable consequences if your code is complex or relies on C/C++ behavior that is implementation-defined or even undefined by the C/C++ standards. What might happen is that your code behaves perfectly well when adding the printf to the code, but breaks again when you remove the printout, or vice versa. By the way, this is a very good reason to strive for MISRA compliance. Another good reason is that printf is a pretty weak tool as it can only display data. The third reason is that to change the behavior of the printout or add more printing statements, you need to re-build the application and download it to the target again. Finally, at some point you will have to go through the code base and remove all the statements you added, even if they are all guarded with #ifdefs.
The power of breakpoints
So, let’s take a break from the preaching to look at the different types of breakpoint available. A breakpoint can, in its simplest form, just be a stop sign at a particular source statement, so execution breaks unconditionally when reaching the right spot. A decent debugger will then let you examine the content of variables, registers and the call stack as well as memory in general. Such a code breakpoint can be very useful in itself, but it can also be associated with an expression whose truth value determines if execution stops or not.
By doing so, you can focus on the interesting cases instead of examining the interesting variables every time execution pass through the breakpoint location. For example, if you want to take a closer look at what is going on in a specific range of value in a loop index variable, you can setup the expression to stop only when the index is in that range rather than stopping each time you hit that code. Of course, you can also construct more complex stop expressions based on any variables that are in scope.
Sometimes you really need to see the value of one or more expressions. An easy way to do this is to use a log breakpoint. A log breakpoint is a breakpoint whose only purpose is to print a message in the debug log window without stopping execution. It is essentially a debugger-supplied printf that can also be combined with a Boolean expression to determine if the message should be generated or not.
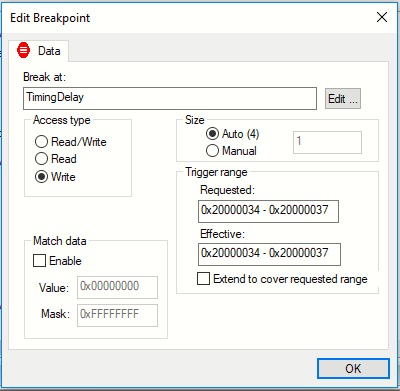
A very powerful type of breakpoint is the data breakpoint. A data breakpoint will trigger when a specific variable or memory location is accessed. This can be extremely helpful if you are trying to figure out why data values in a specific location are not the data you expect. Why would you need to do that, you say? Well, there can be several reasons you may find yourself in that situation, but one of the sources for such issues is pointers. If you use (or abuse) pointers there is a fair chance that at some point you will get some pointer arithmetic wrong, and while reading from or writing to the wrong address might not make the program fall over, it can still produce very strange results. These kind of issues can be very tricky to debug, as the actual bug and the place where you experience the effect are often not related in any way.
Combining data breakpoints (or any type of breakpoint, for that matter) with the call stack window can be very revealing. The call stack window will show you where you came from, which can sometimes be a bit surprising… :-) It also gives you the opportunity to move up and down the call chain and examine parameter values.
Note that some of these types of breakpoints might not always be available, depending on the exact device you are running your program on, and/or the specific debug probe.
Some targets support live reading of memory, so that the debugger can continuously display variable values and other information during execution with a standard debug probe.
A path to enlightenment
If you can stand a few extra buzzwords and adjectives, let’s spend a few lines talking about a debugging tool that is truly amazing. Trace is a way to record the execution and other types of data flow on your device, like interrupt information and other hardware events. For example, viewing combined event data in a timeline can be very revealing about how your system behaves: are your interrupts firing when they should, and how does it correlate with other activity?
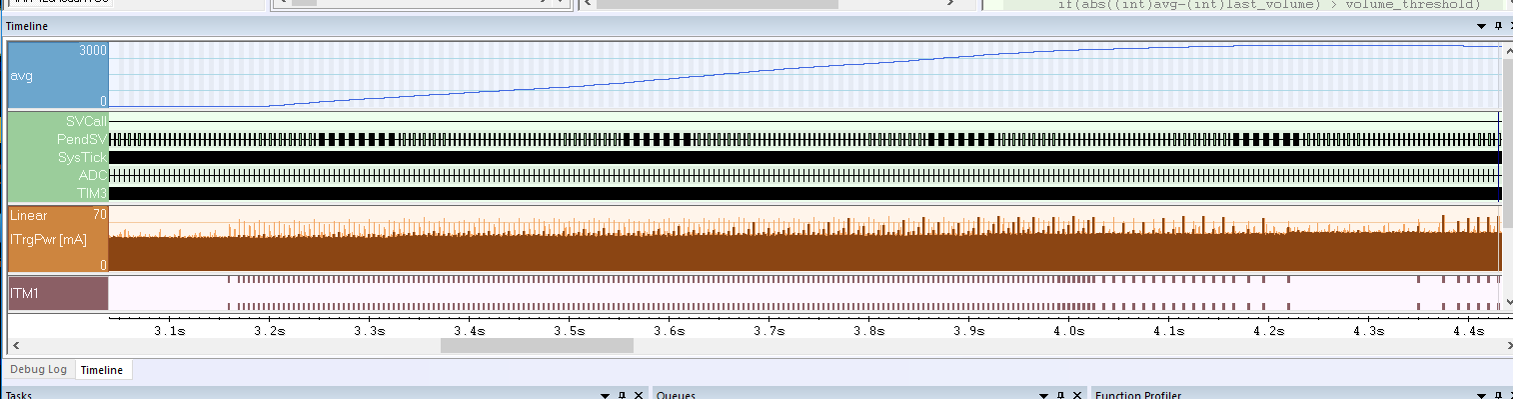
What makes trace a bit more complex than regular debugging is that there are many different types of trace technologies, and different ways to access the trace data. On top of that, you may need a trace-enabled probe. So to utilize the power of trace in the best way for your needs, it is beneficial to think about what you need to do to use trace at the beginning of your project.
- One thing to consider is the choice of device. Does it have trace functionality and if so, what kind?
- Is the device available in versions with and without trace? If so, you may build development versions of your board with trace and go to production without it to keep cost down.
- Trace can also be an enabler for profiling and code coverage data, so thinking up-front about your needs in that area can be beneficial.
High-quality trace tools are designed to take away the pain of trace complexity and use all available trace information, but you still have to figure out your needs on the hardware side. However, investing some time and resources up front in trace as a debug and code quality tool will pay off when you hit that first tricky issue.
The way to increased efficiency
Some of the topics in this article might seem borderline trivial, but the best solutions to tricky problems often are. Finding the root cause of a software problem can take days or even weeks, or it can be a quick and easy process. One way to increase the chance of the latter is not to always reach for a printf statement, but rather spend a moment to think about how to best use your knowledge of the code base in combination with the features of your debugger and trace tools. Over time, you may find that this way of working is a real boost to your productivity and efficiency, not to mention peace of mind.
Article written by Anders Holmberg, General Manager Embedded Development Tools at IAR Systems